![[wikilink]](../graphics/link-external-small-ltr-progressive.svg) ,
≈O(N2.8074) are not considered, partially due to
stability issues. Even faster algorithms, ≈O(N2.37),
exist,
but are even less applicable due to the requirement that N be extremely
large to be faster.
,
≈O(N2.8074) are not considered, partially due to
stability issues. Even faster algorithms, ≈O(N2.37),
exist,
but are even less applicable due to the requirement that N be extremely
large to be faster.
Version 0.2-draft-20250325
This document explores design options for the RISC‑V Matrix extensions currently under discussion, including the Integrated Matrix Extension (IME) and the Attached Matrix Extension (AME). One particular method—accumulating the outer product of two vectors from the source matrixes into a tile of the destination matrix—is relevant for both IME and AME. There are elements of the IME and AME TG charters that need addressing to best exploit the strengths of outer product method, and this document explores why such an approach would be worth pursuing.
This proposal makes the assumption that the matrixes to be multiplied are quite large, and thus must be loaded incrementally. There are applications for matrix multiply by small matrixes that might be stored locally and used multiple times (e.g., a coordinate transform), but this proposal is not targeted at such applications.
The following exposition first presents definitions and theory related to straightforward* matrix multiplication, then explores characteristics of various implementations, leading to the reasoning and explanation for this proposal’s approach to matrix computation.
* This exploration is for classic, or schoolbook, O(N3)
matrix multiplication. Other algorithms, such as
the Strassen algorithm,
≈O(N2.8074) are not considered, partially due to
stability issues. Even faster algorithms, ≈O(N2.37),
exist,
but are even less applicable due to the requirement that N be extremely
large to be faster.
This document uses many concepts and acronyms from the RISC‑V Vector (RVV) extension. A simplified explanation of these items is given below for the reader not well-versed in RVV. The reader should refer to the RVV documentation for more precise definitions and explanations. Some other items are specific to these notes.
,
which was originally a stroage format introduced by Google for AI
algorithms. It consists of simply throwing away (round toward 0) the
low 16 bits of IEEE 754 binary32 (single precision) floating-point
format to save space and padding with 16 zero bits when converting
back to single precision. It has evolved from a storage format into a
computation format, and now many implementations use
round-to-nearest-even when converting from single precision to BF16
and when computing with BF16. It is second of two 16‑bit
floating-point formats, the other being FP16, which was originally
invented for graphics and standardized by IEEE in 2008.
,
which is an API for linear algebra operations such as:
.
.
(also called the inner product) of two equal length
vectors
and is the sum of the products of corresponding elements:
,
which is defined
as .
The BLAS convention is that 𝐶 is
a
matrix, 𝐴 is
a
matrix, and 𝐵 is
a
matrix. Both 𝐴 and 𝐵 can optionally be transposed,
providing three additional forms:
,
which is defined
as .
The BLAS convention is that 𝐴 is
a
matrix, 𝒙 is a 𝑁‑element column vector (i.e., ),
and 𝒚 is a 𝑀‑element column vector (i.e., )..
.
It is only cited in this document for
its OCP Microscaling Formats (MX) Specification,
which specifies small scaled integer and floating-point formats such
as MXFP8 (E5M2 or E4M3), MXFP6 (E3M2 or E2M3), MXFP4 (E2M1), and
MXINT8.
.
is the distance in memory between successive elements, measured either
in bytes or element-size units. Unit stride, where elements are
immediately adjacent, is usually most efficient when caches are based
on spatial locality.
For a two-dimensional array
in row-major order,
which is a Floating-Point format defined by Nvidia that is
significantly faster on their GPUs
than FP32. It has a sign bit, 8 exponent bits, and 11 bits of
precision (10 stored, 1 hidden bit implied for normalized), for a
total of 19 bits. The other 13 bits of the 32‑bit container are
unused or only used to round, so this format saves no space in memory;
it exists for faster computation only*..
If 𝐴 is an matrix and 𝐵 is an matrix
the matrix product is defined to be the matrix
such that
Equivalently,
is the inner or dot product![]() of row 𝑖 of 𝐴 and column 𝑗 of 𝐵. Unless
parallel summation techniques are employed, the inner product is the
sequential portion of the computation.
of row 𝑖 of 𝐴 and column 𝑗 of 𝐵. Unless
parallel summation techniques are employed, the inner product is the
sequential portion of the computation.
Straightforward matrix multiplication is multiplications and additions with each matrix element being independent of the others but potentially sequential due the inner product additions. The multiplications are all independent (potentially done in parallel), but only of the additions are parallel when floating-point rounding is preserved. With unbounded hardware, the execution time of matrix multiply with floating-point rounding is where is the add latency. This is achieved by using multiply/add units 𝑘 times every cycles, but a smarter implementation would use units pipelined to produce a value every cycle, thereby adding only additional cycles for the complete result.
The parallel portion of the computation is called
the outer product.
If 𝒖 is a 𝑚‑element vector and 𝒗 is a
𝑛‑element vector,
then the outer product is defined to be the matrix
i.e.
The outer product is a fully parallel computation of multiplications.
Using this formulation, the matrix product can be expressed as the sum of 𝑘 outer products of the columns of 𝐴 with the rows of 𝐵:
where is column 𝑙 of 𝐴 and is row 𝑙 of 𝐵 and is the outer product operator.
The matrix multiplication and outer product definitions (i.e., the equations above) work both when the elements are scalars or are themselves matrixes. For example, could be a matrix that is sum of the products of a row of matrixes from 𝐴 with a column of matrixes from 𝐵. Such submatrixes are called tiles.
It is possible to code the above in many ways, but the most common is simply:
for i ← 0 to m-1
for j ← 0 to n-1
for l ← 0 to k-1
c[i,j] ← c[i,j] + a[i,l] * b[l,j]
Unfortunately, this an inefficient use of memory bandwidth when the
matrixes are large. However, by recoding the matrix multiplication,
efficiency can be restored. As noted above, the same equations apply
when the elements are scalar values, or are themselves matrixes.
When , , ,
are matrixes rather than scalars, they are called tiles. When a
matrix multiplication is performed by tiles, typically the elements of
𝐶 are loaded into local storage, and all of the operations
targeting that tile are performed, and then that local storage is
written back to 𝐶. In this scenario, each element of 𝐶
is read once and written once. Matrix multiplication of elements (or
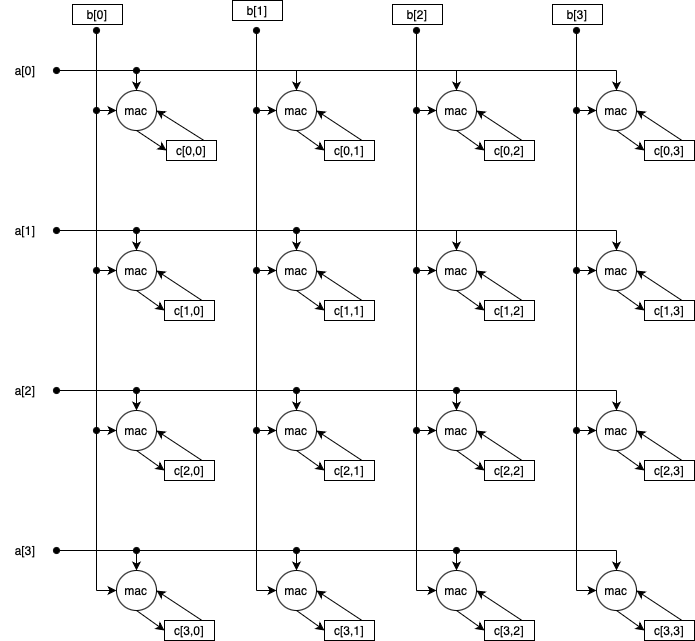
matrixes as tiles) is illustrated in the following figure showing
multiplying elements (or tiles) from a column of of 𝐴 with
elements (or tiles) from a row of 𝐵, accumulating to an element
(tile) of the product 𝐶:

Larger tiles reduce references to memory and increase parallelism opportunities, but require more local storage.
It was noted above that each element of 𝐶 is read once and written once. In contrast, the elements of 𝐴 are read times and the elements of 𝐵 are read times.
Note also that software often transposes 𝐴 or 𝐵 prior to performing the matrix multiply, to avoided strided memory accesses. The matrix transposed depends on whether row or column-major order is used and the access pattern of the algorithm employed. The appropriate transpose is not reflected in the material below, and is left as an exercise to the reader.
The description above is represented by the tiling loops shown below, with loops for the tile multiplication replaced by a optimized kernel:
for ti ← 0 to m-1 step s // tile i
for tj ← 0 to n-1 step t // tile j
for tl ← 0 to k-1 step r // tile l
matmul(c[ti..ti+s-1,tj..tj+t-1],
a[ti..ti+s-1,tl..tl+r-1],
b[tl..tl+r-1,tj..tj+t-1])
Since c[ti..ti+s-1,tj..tj+t-1] is inner loop invariant,
given the above loop order, it can be allocated to local storage
(represented by acc below):
for ti ← 0 to m-1 step s // tile i
for tj ← 0 to n-1 step t // tile j
acc[0..s-1,0..t-1] ← c[ti..ti+s-1,tj..tj+t-1]
for tl ← 0 to k-1 step r // tile l
matmul(acc[0..s-1,0..t-1],
a[ti..ti+s-1,tl..tl+r-1],
b[tl..tl+r-1,tj..tj+t-1])
c[ti..ti+s-1,tj..tj+t-1] ← acc[0..s-1,0..t-1]
Other orderings of the i,j,l loops are possible, but are
generally inferior to keeping 𝐶 tiles in registers during the
inner loop, as summarized in the following table. References to
𝐶 have to be both loaded and stored, represented below by the
factor of 2, and in addition the factor
of
represents the ratio of the bits in 𝐴 and 𝐵 elements to the number of
bits in elements of 𝐶, i.e., the widening
ratio.
represents no widening. Typically, FP32 and FP64 do not require
widening (though widening FP32 to FP64 is seen occasionally). Smaller
data formats, such as FP16, BF16, FP8, FP4, and int8 are usually
accumulated in a wider format such as FP32 or int32, so for FP8 products
with FP32
accumulation, ,
and for FP16 with FP32
accumulation, .
| Order | Inner loop invariant | Inner 1 | Inner 2 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| i,j,l | c[i,j] | a[i,l] | b[l,j] | |||||||||||
| i,l,j | a[i,l] | c[i,j] | b[l,j] | |||||||||||
| j,i,l | c[i,j] | a[i,l] | b[l,j] | |||||||||||
| j,l,i | b[l,j] | c[i,j] | a[i,l] | |||||||||||
| l,i,j | a[i,l] | c[i,j] | b[l,j] | |||||||||||
| l,j,i | b[l,j] | c[i,j] | a[i,l] | |||||||||||
| Order | Total |
|
|
|---|---|---|---|
| i,j,l | |||
| i,l,j | |||
| j,i,l | |||
| j,l,i | |||
| l,i,j | |||
| l,j,i |
The above table makes it clear why the 𝐶 tile is typically
kept stationary
in the inner loop, as it must be both loaded and
stored (a factor of two in references), and for some data formats, may
be wider than the source matrixes, which is potentially another factor
of 2, 4, or 8 again (the table provides
a
widening example, with the combination being a factor of 8).
With 𝐶 held in registers—no loads or stores required—tile multiplication requires loads from 𝐴 and 𝐵. Above, it was observed that 𝑚𝑛 of matrix multiplications are parallel, and equivalently 𝑠𝑡 of a tile are parallel.
For practical implementation, hardware is bounded and should lay out in a regular fashion. The number of multiply/add units is usually much smaller than , in which case there is flexibility in how these units are allocated to the calculations to be performed, but the allocation that minimizes data movement between the units and memory is to complete a tile of 𝐶 using the hardware array before moving on to a new tile (see preceding section).
To discuss implementation, it helps to consider the number of bits that can be loaded in a single cycle (the width of the cache feeding the vector unit). This is designated MLEN hereinafter. It is typically more useful to use MLEN/SEW—the number of elements that can be loaded in a single cycle—which will now be designated 𝑉. Loads of less than 𝑉 elements do not efficiently use the cache datapaths of the processor. Loads of 𝐿 ≥ 𝑉 elements take cycles and may be appropriate, but they are not necessarily more efficient than doing that many independent 𝑉‑element loads.
The other important implementation parameter is the add latency Δ. The multiply/add units are usually pipelined so that N units will accomplish multiply/adds in cycles. Turning this around, if there are W parallel multiply/adds to be accomplished, then it is appropriate to use multiply/add units to accomplish this computation, starting a new batch of 𝑊 every Δ cycles. Using less than units increases the time, and using more units leaves the units underutilized. In most cases . However, carry-save arithmetic can result in , creating possibilities to be discussed later.
For floating-point formats, the sums are typically done sequentially from 1 to 𝑘 to give the same rounding as the scalar implementation, which results in the latency when pipelined. The order of integer summation is not constrained, and is considerably faster, with possible using carry-save arithmetic. While it is possible to use more parallel techniques for floating-point summation, this is often avoided due to rounding differences, and as a consequence the outer product is often the parallel portion of the computation, and the inner product is the sequential portion. For integer combining into a single 𝑞‑element computation with carry-save arithmetic is possible.
For efficient loads, we load at least 𝑝𝑉 elements from 𝐴 and 𝑞𝑉 elements from 𝐵. These loads take cycles (the minimum takes 2 cycles). The parallel computation is then multiply/adds, so using units results in balanced load and compute cycles. The units are fully utilized for . For example, for the minimum is balanced using fully utilized multiply/add units. The multiply/add units are underutilized for . The underutilization can be solved by increasing 𝑝 and/or 𝑞 (thereby increasing the parallel computation). For even Δ, is one possibility, in which case loading elements from each of 𝐴 and 𝐵, taking Δ total cycles, making the parallel computation . The computation is performed using multiply/add units for Δ cycles. For the typical floating-point add latency this simplifies to units for 4 cycles.
Summarizing the above for the common cases, the analysis suggests that integer computation () use 𝑉‑element loads and units with balanced 2‑cycle load and compute into a 𝑉 × 𝑉 tile. For floating-point computation (), use ‑element loads and pipelined units with balanced 4‑cycle load and compute into a tile. When supporting both integer and floating-point, it appropriate to set the tile size based on meeting the performance requirements for each data type, and then using that tile storage for other data types. For example, if FP8 has the most demanding performance requirement, then the tile size would be at least and then int8 might also use that tile size, despite only requiring 𝑉 × 𝑉. The larger int8 tile size results in fewer references to the upper levels of the memory hierarchy, and therefore better energy efficiency.
In most systems, the maximum tile size will either be a square power of two, e.g., 2×2, 4×4, 8×8, … 128×128, or a rectangle of a power of two and twice that, e.g., 4×2, 8×4, … 256×128. In a given problem, most of the operations will be done with the maximum tile size, with the remainder being the leftover edges. For example, with a maximum tile size of 64×64, a 1000×2000 by 2000×1500 multiplication yielding a 1000×1500 product would use tiles of 64×64 15×23=345 times with the last row of tiles being be 23 tiles of 40×64, the last column of tiles being 15 tiles of 64×28, and final corner would employ a 40×28 tile.
Rectangular tiles might use , computing a tile. The loads would take 3 cycles, which does not cleanly divide , which is one reason square tiles are more frequently employed; is only integral in a limited number of cases.
Efficient parallel computation of matrix multiplication becomes more challenging due to the storage requirements for 𝐶 tiles as the data width is reduced. Above, elements (typically ) for floating-point and 𝑉 elements for integer were derived as efficient load widths that balance load and compute and fully utilize multiply/add units. For these load widths the outer product is and computation respectively. Floating-point requires bits of storage for SEW ≥ 32, which is proportional to the inverse of SEW. With widening to 32 bits for narrower floating-point data types (SEW < 32), the requirement is , which is quadratic in the 32/SEW. Thus FP8 requires 𝐶 tiles 16 times larger than FP32, and FP4 requires 4 times larger than FP8. Integer is generally SEW < 32, and the storage requirement is , Examples of these sizes are given in the table below.
| SEW MLEN |
Δ=1 | Δ=4 | |||||
|---|---|---|---|---|---|---|---|
| int4 | int8 | FP4 | FP8 | FP16 | FP32 | FP64 | |
| 128 | 32768 | 8192 | 131072 | 32768 | 8192 | 2048 | 1024 |
| 256 | 131072 | 32768 | 524288 | 131072 | 32768 | 8192 | 4096 |
| 512 | 524288 | 131072 | 2097152 | 524288 | 131072 | 32768 | 16384 |
| 1024 | 2097152 | 524288 | 8388608 | 2097152 | 524288 | 131072 | 65536 |
This calculation can be inverted to give the MLEN and MACs/cycle for various 𝐶 tile sizes. Here again we assume 32‑bit accumulation for SEW≤32 (if 16‑bit accumulation is possible for SEW≤8 then savings are possible). For bits 𝑏, the number of tile elements is for SEW≤32 and for FP64. The MACs/cycle is half of tile elements for Δ=1 integer and a quarter for Δ=4 floating-point. The square root of the tile elements is the outer product elements. This times SEW is the MLEN.
| SEW MLEN |
Δ=1 | Δ=4 | ||||
|---|---|---|---|---|---|---|
| int4 | int8 | FP4 | FP8 | FP16 | FP32 | |
| 2048 | 64 | 128 | ||||
| 8192 | 64 | 128 | 64 | 128 | 256 | |
| 32768 | 128 | 256 | 64 | 128 | 256 | 512 |
| 131072 | 256 | 512 | 128 | 256 | 512 | 1024 |
| 524288 | 512 | 1024 | 256 | 512 | 1024 | 2048 |
| 2097152 | 1024 | 2048 | 512 | 1024 | 2048 | 4096 |
| 8388608 | 2048 | 4096 | 1024 | 2048 | 4096 | |
| Bits | Δ=1 int4 / int8 |
Δ=4 FP4 ⋯ FP32 |
|---|---|---|
| 2048 | 16 | |
| 8192 | 128 | 64 |
| 32768 | 512 | 256 |
| 131072 | 2048 | 1024 |
| 524288 | 8192 | 4096 |
| 2097152 | 32768 | 16384 |
| 8388608 | 131072 | 65536 |
| Bits | Δ=4 FP64 | |
|---|---|---|
| MLEN | MACs/cycle | |
| 1024 | 128 | 4 |
| 4096 | 256 | 16 |
| 16384 | 512 | 64 |
| 65536 | 1024 | 256 |
| 262144 | 2048 | 1024 |
The following series of transforms demonstrates how the simple, schoolbook matrix multiply written as three nested loops shown below is transformed for the RISC‑V Vector ISA using outer products. (Note that the pseudo-code switches from 1‑origin indexing of Matrix Algebra to 0‑origin indexing of computer programming. Note also that, for clarity, the pseudo-code below does not attempt to handle the case of the matrix dimensions not being a multiple of the tile size.)
for i ← 0 to m-1
for j ← 0 to n-1
for l ← 0 to k-1
c[i,j] ← c[i,j] + a[i,l] * b[l,j]
The scalar version above would typically then move c[i,j]
references to a register to reduce the load/store to multiply/add ratio
from 4:1 to 2:1.
for i ← 0 to m-1
for j ← 0 to n-1
acc ← c[i,j]
for l ← 0 to k-1
acc ← acc + a[i,l] * b[l,j]
c[i,j] ← acc
However, in the vector version this step is delayed until after tiling. For vector, the above code is first tiled to become the following (here VL=VLEN/SEW):
// iterate over 16×VL tiles of C
for ti ← 0 to m-1 step 16
for tj ← 0 to n-1 step VL
// add product of sixteen columns of a (a[ti..ti+15,0..k-1])
// and sixteen rows of b (b[0..k-1,tj..tj+VL-1]) to product tile
for i ← 0 to 15
for j ← 0 to VL-1
for l ← 0 to k-1
c[ti+i,tj+j] ← c[ti+i,tj+j] + a[ti+i,l] * b[l,tj+j]
The above code is then modified to use sixteen vector registers
(EMUL≤1) as a 16×VL tile accumulator, and all i
and j loops replaced by vector loads. (For VL=16 and
EMUL≤1, this requires VLEN≥128 for 8‑bit 𝐶 data, 256
for 16‑bit 𝐶 data, 512 for 32‑bit 𝐶 data, and 1024 for
64‑bit 𝐶 data. For widening multiply/adds (EMUL=2*LMUL) where
LMUL=1 and EMUL=2, only 8×VL tiles may be used as the destination
will be even/odd register pairs.)
for ti ← 0 to m-1 step 16 // tile i
for tj ← 0 to n-1 step VL // tile j
// copy to accumulator
v0 ← c[ti+ 0,tj..tj+VL-1] // 16 VL-element vector loads
v1 ← c[ti+ 1,tj..tj+VL-1] // to use vector registers
v2 ← c[ti+ 2,tj..tj+VL-1] // as an 16×VL accumulator
v3 ← c[ti+ 3,tj..tj+VL-1]
⋮
v15 ← c[ti+15,tj..tj+VL-1]
// add product of a[ti..ti+15,0..k-1]
// and b[0..k-1,tj..tj+VL-1] to tile
for l ← 0 to k-1
vb ← b[l,tj..tj+i+VL-1] // VL-element vector load
v0 ← v0 + a[ti+ 0,l] * vb // vector * scalar
v1 ← v1 + a[ti+ 1,l] * vb
v2 ← v2 + a[ti+ 2,l] * vb
v3 ← v3 + a[ti+ 3,l] * vb
⋮
v15 ← v15 + a[ti+15,l] * vb
// copy accumulator back to tile
c[ti+ 0,tj..tj+VL-1] ← v0 // 16 VL-element vector stores
c[ti+ 1,tj..tj+VL-1] ← v1 // to store accumulator
c[ti+ 2,tj..tj+VL-1] ← v2 // back to C tile
c[ti+ 3,tj..tj+VL-1] ← v3
⋮
c[ti+15,tj..tj+VL-1] ← v15
The inner loop has:
This is a total of 57 instructions; a combination of IPC ≥ 2 and VLEN/DLEN > 1 is required to achieve VL multiply/adds per cycle.
One limitation of the RISC‑V vector instruction set is the lack of a vector × scalar instruction where the scalar is an element of a vector register. Extending the RISC‑V Vector instruction set would save many scalar loads and address adds in the above loop, but would require an efficient strided vector load or transposing the 𝐴 matrix.
For SEW < 64 a different possible addition to the
RISC‑V Vector (RVV) instruction set would be a vector-scalar
multiply/accumulate that takes the scalar from an offset in the scalar
register. It is then possible to pack 64/SEW (2, 4, or 8) values
into f
or x registers by loading
with FLD
or LD, and then the extension would
allow .vf
or .vx to specify a 3-bit immediate
specifying which portion of the scalar register register to use as the
scalar operand (and disabling the RISC‑V NaN-boxing check for this
packed SIMD reference). This might require a wider vector instruction
word. Given the stride on the scalar loads, this SIMD packing would
require unrolling the l loop 64/SEW times. The primary
advantage of such an extension is the application
to matrix-vector products.
Computational intensity is defined as the ratio of the number of element-level multiply/add operations to the number of elements loaded. The vector code above performs multiply/adds for elements loaded. For example, this is a computational intensity of 8, 10.7, and 12.8 for VL values 16, 32, and 64 respectively.
The vector code above requires elements of register storage.
Besides the obvious parallelism advantage, another improvement is that each element of the 𝐴 matrix is used VL times per load, and each element of the 𝐵 matrix is used sixteen times per load, which improves energy efficiency. However, one limitation of the vector implementation of matrix multiply is the limited number of multiply/add units that can be used in parallel. It is obvious that the above can use VL units in parallel (one for each element of the vectors). Slightly less obvious is that for VL=16 an implementation could employ units to execute the above code, issuing groups of vector instructions in a single cycle, and parceling these vector operations out to the various units to proceed in parallel. After instructions, the next group can be issued to the pipelined units. It would be necessary to provide substantial additional Vector Register File (VRF) bandwidth to support this. If instruction issue is limiting, an instruction that packaged groups of the above vector operations could be provided. Given this observation, there are three reasons to add a more robust matrix extension to RISC‑V:
The next sections introduce a possible RISC‑V Matrix Extension that accomplishes all three of the above goals.
While it is obvious, for reference, the following pseudo-code gives the widening form of the RVV matrix multiply (LMUL=1 EMUL=2).
for ti ← 0 to m-1 step 8 // tile i
for tj ← 0 to n-1 step VL // tile j
// copy to accumulator
v0 ← c[ti+0,tj..tj+VL-1] // 8 VL-element vector loads (LMUL=2)
v2 ← c[ti+1,tj..tj+VL-1] // to use vector register pairs
v4 ← c[ti+2,tj..tj+VL-1] // as an 8×VL accumulator
v6 ← c[ti+3,tj..tj+VL-1]
v8 ← c[ti+4,tj..tj+VL-1]
v10 ← c[ti+5,tj..tj+VL-1]
v12 ← c[ti+6,tj..tj+VL-1]
v14 ← c[ti+7,tj..tj+VL-1]
// add product of a[ti..ti+7,0..k-1]
// and b[0..k-1,tj..tj+VL-1] to tile
for l ← 0 to k-1
vb ← b[l,tj..tj+i+VL-1] // VL-element vector load
v0 ← v0 + a[ti+0,l] * vb // vector * scalar
v2 ← v2 + a[ti+1,l] * vb
v4 ← v4 + a[ti+2,l] * vb
v6 ← v6 + a[ti+3,l] * vb
v8 ← v8 + a[ti+4,l] * vb
v10 ← v10 + a[ti+5,l] * vb
v12 ← v12 + a[ti+6,l] * vb
v14 ← v14 + a[ti+7,l] * vb
// copy accumulator back to tile
c[ti+0,tj..tj+VL-1] ← v0 // 8 VL-element vector stores
c[ti+1,tj..tj+VL-1] ← v2
c[ti+2,tj..tj+VL-1] ← v4
c[ti+3,tj..tj+VL-1] ← v6
c[ti+4,tj..tj+VL-1] ← v8
c[ti+5,tj..tj+VL-1] ← v10
c[ti+6,tj..tj+VL-1] ← v12
c[ti+7,tj..tj+VL-1] ← v14
It is desirable to match the number of multiply/add units to the load bandwidth when practical, as this results in a balanced set of resources (memory and computation are equally limiting). We use to represent the vector load bandwidth as the number of elements per cycle. Assuming that loads and computation are done in parallel, next we ask what is the tile size that balances results in equal time loading and computing. We have already seen that the multiply/adds in a matrix multiply is O(N3) but with O(N2) parallelism, so the time can be made as fast as O(N). However loading the data from memory is O(N2), so with sufficient hardware, data load time will be O(N) times the compute time. When load time grows quadratically with problem size while compute time grows linearly, a balanced system will scale up the compute hardware to match the load bandwidth available but not go any further. Of course, to achieve O(N) compute time requires O(N2) hardware, which is feasible for typical T×T matrix tiles, but usually not for the entire problem size N. Conversely, for balanced systems, when load bandwidth increases linearly, the computation array increases quadratically.
Since a vector load provides 𝑉 elements in a single cycle, it makes sense to find the tile size that matches this load bandwidth. This turns out to be a tile of . This tile can be computed by 𝑉 outer products. Take one cycle to load 𝑉 elements from 𝐴 and one cycle to load 𝑉 elements from 𝐵. Processing these values in two cycles matches load bandwidth to computation. For , a array of multiply/add units with accumulators (two per multiply/add unit) accomplishes this by taking the outer product of all of the vector (from 𝐴) and the even elements of the vector (from 𝐵) in the first cycle, and all of with the odd elements of in the second cycle. The full latency is cycles, but with pipelining a new set of values can be started every two cycles. For , using a pipelined array for cycles is a natural implementation but does not balance load cycles to computation cycles. For example, for , a array completes the outer product in 4 cycles, which is half of the load bandwidth limit. For there are multiple ways to match the load bandwidth and adder latency. A good way would be to target a accumulation tile taking four load cycles and four computation cycles, but this requires accumulators, with four accumulators for each multiply/add unit. The method that minimizes hardware is to process two tiles of 𝐶 in parallel using pipelined multiply/add units by doing four cycles of loads followed by two 2‑cycle outer products to two sets of accumulators. For example, the loads might be 𝑉 elements from an even column of 𝐴, 𝑉 elements from an even row of 𝐵, 𝑉 elements from an odd column of 𝐴, and 𝑉 elements from an odd row of 𝐵. The computation would consist of two outer product accumulates, each into accumulators (total ). The total latency is seven cycles but the hardware is able to start a new outer product every four cycles by alternating the accumulators used, thereby matching the load bandwidth. If any of these array sizes is too large for the area budget, then it will be necessary to reduce performance, and no longer match the memory hierarchy. However, in 2024 process nodes (e.g., 3 nm), it would take fairly large 𝑉 to make the multiply/add unit array visible on a die.
A
multiply/add array with one accumulator per unit is illustrated below
for :
The above array is not suggested for use, as compute exceeds the load bandwidth.
Instead one proposal developed above is
a
multiply/add array with two accumulators per unit for two cycle
accumulation
to
accumulators. This is illustrated below
for :

A
multiply/add array with four accumulators per unit
for
accumulation is illustrated below
for .
Such an array would be used four times over four cycles, each cycle
sourcing from a different combination
of 𝑉
elements from
the
elements loaded from 𝐴 and
the
elements loaded from 𝐵.
This is one possibility explained above for
supporting
or simply to improve performance energy efficiency
for .
For the general case of a tile, the load cycles are and the computation cycles using a array are . Balancing these is not always possible.
The sequence for is illustrated below, using superscripts to indicate cycle numbers, as in to indicate accumulators being zero on cycle 0, the value loaded on cycle 0, the vector loaded on cycle 1, the result of the first half of the two-cycle latency outer product, the result of the second half of the outer product, etc.
The following series of transforms demonstrates how the simple, classic matrix multiply written as three nested loops shown below is transformed to use tiles with an outer product multiply/add/accumulator array. For the tiling, usually TR=TC=V or TR=TC=2V, but there may be implementations that choose other vector lengths for microarchitectural reasons, and this should be supported.
for i ← 0 to m-1
for j ← 0 to n-1
for l ← 0 to k-1
c[i,j] ← c[i,j] + a[i,l] * b[l,j]
The above code is then tiled to become the following:
// iterate over TR×TC tiles of C
for ti ← 0 to m-1 step TR
for tj ← 0 to n-1 step TC
// add product of a[ti..ti+TR-1,0..k-1]
// and b[0..k-1,tj..tj+TC-1] to tile
for i ← 0 to TR-1
for j ← 0 to TC-1
for l ← 0 to k-1
c[ti+i,tj+j] ← c[ti+i,tj+j] + a[ti+i,l] * b[l,tj+j]
The above code is modified to use an accumulator tile:
for ti ← 0 to m-1 step TR
for tj ← 0 to n-1 step TC
// copy to accumulator
for i ← 0 to TR-1
for j ← 0 to TC-1
acc[i,j] ← c[ti+i,tj+j]
// add product of a[ti..ti+TR-1,0..k-1]
// and b[0..k-1,tj..tj+TC-1] to tile
for i ← 0 to TR-1
for j ← 0 to TC-1
for l ← 0 to k-1
acc[i,j] ← acc[i,j] + a[ti+i,l] * b[l,tj+j]
// copy accumulator back to tile
for i ← 0 to TR-1
for j ← 0 to TC-1
c[ti+i,tj+j] ← acc[i,j]
The above code is then vectorized by moving the l loop
outside and the i and j loops into the
outer product instruction:
for ti ← 0 to m-1 step TR
for tj ← 0 to n-1 step TC
for i ← 0 to TR-1
acc[i,0..TC-1] ← c[ti+i,tj..tj+TC-1] // TC-element vector load + acc write
for l ← 0 to k-1
va ← a[ti..ti+i+TR-1,l] // TR-element vector load col of A
vb ← b[l,tj..tj+i+TC-1] // TC-element vector load row of B
acc ← acc + outerproduct(va, vb) // 2-cycle outer product instruction
for i ← 0 to TR-1
c[ti+i,tj..tj+TC-1] ← acc[i,0..TC-1] // acc read + TC-element vector store
where the outerproduct(va, vb) operation invoked above is defined as follows:
for i ← 0 to TR-1 for j ← 0 to TC-1 product[i,j] ← va[i] * vb[j] return product
An implementation would usually choose TR=TC=T for most of the
computation so that the RISC‑V vector length
register VL would not need to be swapped when
switching between loads to va and loads
to vb. Such switching will be necessary for tiles at the
right and bottom of 𝐶 when the bounds are not multiples of TC and TR,
but that would be in a separate TR≠TC loop.
The above performs multiply/adds for elements loaded. For a square tile , this is a computational intensity of , and for the rectangular tile , this is a computational intensity of , which is slightly better than the square case. Compared to the earlier vector method, this has identical computational intensity for the same tile sizes, but which is not limited by the number of vector registers (it uses only two), and thus may grow as large as value of 𝑇 the implementation chooses to support.
The vector code above performs multiply/adds for elements stored. Compared to the earlier vector method, this has identical storage requirement for the same tile sizes. However, accumulator storage is much cheaper than vector register file storage, which is not reflected in the storage requirement. Also, this method supports much larger and , which at larger sizes is almost entirely distributed, low-power accumulator storage.
In the Matrix Algebra section it was observed that cycle count for matrix multiplication with the smarter variant of unbounded multiply/add units (i.e., units) pipelined to produce a value every cycle takes cycles. It is worth answering how the above method fares relative to this standard applied to a single tile. Because we cut the number of multiply/add units in half to match the load bandwidth, we expect at least twice the cycle count, and this expectation is met: matching a memory system that delivers 𝑉 elements per cycle, a tile of processed by an array of multiply/add units () produces the tile in cycles. It may help to work an example. For a memory system delivering one 512‑bit cache block per cycle and 16‑bit data (e.g., BF16), , and the 32×32 tile is produced using 2 vector loads and one 2‑cycle outer product instruction iterated 32 times taking 64 cycles yielding 512 multiply/adds per cycle. However, this does not include the time to load the accumulators before and transfer them back to 𝐶 after. When this 64 cycle tile computation is part of a 1024×1024 matrix multiply, this tile loop will be called 32 times for each tile of 𝐶. If it takes 64 cycles to load the accumulators from memory and 64 cycles to store back to memory, then this is 64+32×64+64=2176 total cycles. There are a total of 1024 output tiles, so the matrix multiply is 2228224 cycles (not counting cache misses) for 10243 multiply/adds, which works out to 481.88 multiply/adds per cycle, or 94% of peak.
Note that there is no point in loading entire tiles, as this would not benefit performance. Rows and columns are loaded and consumed, and not used again. Storing whole tiles of the 𝐴 and 𝐵 matrixes would only be useful in situation when such a tile is used repeatedly, which does not occur in a larger matrix multiply. This does occur for the accumulation tile of the 𝐶 matrix, which does make that worth storing locally. The question is where it should be stored.
It is worth noting that the l loop above can be unrolled to
create more scheduling opportunities as shown below:
for ti ← 0 to m-1 step TR
for tj ← 0 to n-1 step TC
for i ← 0 to TR-1
acc[i,0..TC-1] ← c[ti+i,tj..tj+TC-1] // TC-element vector load + acc write
for l ← 0 to k-1 step 4
acc ← acc + outerproduct(a[ti..ti+i+TR-1,l+0], b[l+0,tj..tj+i+TC-1])
acc ← acc + outerproduct(a[ti..ti+i+TR-1,l+1], b[l+1,tj..tj+i+TC-1])
acc ← acc + outerproduct(a[ti..ti+i+TR-1,l+2], b[l+2,tj..tj+i+TC-1])
acc ← acc + outerproduct(a[ti..ti+i+TR-1,l+3], b[l+3,tj..tj+i+TC-1])
for i ← 0 to TR-1
c[ti+i,tj..tj+TC-1] ← acc[i,0..TC-1] // acc read + TC-element vector store
The transpose and packing phase would then arrange the above
non-contiguous vectors to be packed contiguously so that 4×TR and
4×TC element loads would be used. It is also apparent that either
the outerproduct operation should be at least Δ cycles so that
the acc dependency does not stall. It would also be
possible to implement an inner product operation of reduced latency for
the above (e.g., using carry-save arithmetic).
The bandwidth of reads and writes to outer product accumulators far exceeds what a Vector Register File (VRF) generally targets, which suggests that that these structures be kept separate. Also the number of bits in the accumulators is potentially large relative to VRF sizes. Increasing the bandwidth and potentially the size of the VRF to meet the needs of outer product accumulation is not a good solution. Rather the accumulator bits should located in the multiply/add array, and be transferred to memory when a tile is completed. This transfer might be one row at a time through the VRF, since the VRF has the necessary store operations and datapaths to the cache hierarchy. The appropriateness of separate accumulator storage may be illustrated by examples. A typical vector load width might be the cache block size of 512 bits. This represents 64 8‑bit elements. If the products of these 8‑bit elements is accumulated in 16 bits (e.g., int16 for int8 or fp16 for fp8), then for , 16×642 = 65536 bits of accumulator are required. The entire VRF might need only half as many bits, and these bits require more area than accumulator bits, as the VRF must support at least 4 read ports and 2 write ports for parallel execution of vmacc.vv and a vector load or vector store. If vector registers are renamed, then VRF bits are even more costly. In contrast, accumulator storage within the multiply/add array is local, small, and due to locality consumes negligible power. As another example, consider the same 512 bits as sixteen IEEE 754 binary32 elements with . The method for this latency suggests a 16×8 array of binary32 multiply/add units with 2048 32‑bit accumulators, which is again a total of 65536 bits of accumulator storage, but now embedded in much larger multiply/add units.
The number of bits require for accumulation needs to be determined (the example above is not meant to be anything other than an example). Recently the TF32 format appears to be gaining popularity for AI applications, and so accumulation in TF32 for BF16 inputs is one option. However, this needs further investigation.
An outer product instruction is an easy addition to the RISC‑V vector extension, but it needs be made scalable. Accumulators are defined to be 32 bits with an option to use pairs of accumulators for 64‑bit data. The primary parameter for implementations to choose will be the number of accumulators. This will be a square T×T array for holding a tile of the 𝐶 matrix up to this size. Implementations will then choose the number of multiply/add units that are used to calculate the inner product of vectors of T elements. For example, this document explored choosing T=V for load bandwidth matching for Δ≤2 and T=2V for Δ=4*, but an implementation might choose a smaller T value to reduce the hardware cost, or a reduced number of multiply/add units, or both. Typically these units would also be organized as an array of M×N units. In this case there are accumulators per unit.
* More generally, matches load bandwidth for , but given that powers of two are most appropriate for tile size, only is usually of interest.
The number of rows and columns in the 𝐶 tile may be less than T. The number of tile columns is less than T when processing the last column of tiles when k is not a multiple of T. The number of tile rows is less than T when processing the last row of tiles of 𝐶 when m is not a multiple of T. Software is expected to use the msetcli instruction to set the TR CSR to the number of rows in the 𝐶 tile as min(x[rs1], T×LMUL), and to use the msetrli instruction to set the TC CSR to the number of columns in the 𝐶 tile as min(x[rs1], T×LMUL).
Most of the 𝐶 matrix (i.e except at its right and bottom edges), will be processed with TR = T and TC = T. Here a loop iterated T times will load vectors from the 𝐴 and 𝐵 matrixes into two vector registers (e.g., va and vb) and the instruction vopacc.avv ma0, va, vb used to accumulate the outer product of these vectors as shown in the following example for 8-bit data, which assumes that the 𝐴 and 𝐵 has been packed as in BLIS for in-stride access:
loop: vle8.v va, (ra); add ra, ra, rt vle8.v vb, (rb); add rb, rb, rt vfopacc.avv ma0, va, vb;bne ra, rn, loop
The packing required is implementation-specific, and should be determined by use of a msetcli/msetrli pair of instructions.
When TR ≠ TC software will use a different loop that loads TR elements from 𝐴 and TC elements from 𝐵. This will involve setting VL to these two values in the loop rather than outside of the loop, and will require more instructions as a result. Some amount of unrolling may amortize the writes to VL, e.g., setting VL to TR and doing four loads from 𝐴, then setting setting VL to TC and doing four loads from 𝐵, and then doing four outer products.
This proposal implements the above by using the existing RVV VL CSR to hold the number of tile columns, and adds a TR CSR for the number of tile rows. These are set by the msetcli/msetrli pair of instructions that set VL and TR for columns and rows in an analogous fashion to vsetvli.
The msetcli/msetrli instructions set VL and TR to the minimum of target lengths for their outer product instruction and their rs1 argument. For some implementations the target rows and columns will be chosen to be the larger of the hardware array rows and columns and 𝑉, the number of elements that can be loaded in a single cycle. Other implementations may choose some multiple of 𝑉 instead, and then iterate as shown below for a square hardware array:
for l ← 0 to VL step T acc ← acc + outerproduct(va[l..min(l+T-1,TR)], vb[l..min(l+T-1,VL)])
or as shown below for a rectangle hardware array:
ka ← 0 kb ← 0 while ka < TR & kb < VL acc ← acc + outerproduct(va[ka..min(ka+TR-1,TR)], vb[kb..min(kb+TC-1,VL)]) ka ← ka + TR kb ← kb + TC
For msetcli/msetrli to set the appropriate values, it will be necessary to add a floating-point flag. For integer, usually Δ=1 (and Δ<1 is possible with carry-save arithmetic), but floating-point may have 2≤Δ≤4 depending on SEW, and earlier it was seen that Δ≤2 and Δ=4 might be handled differently.
At a high-level, this proposal would add state and instructions along the lines of the following to the RISC‑V Vector Extension. The details would be developed as appropriate if this general approach is accepted for further development.
A goal of the following is to allow the microarchitecture to provide whatever size outer product array is appropriate for a given SEW (and thus V) and Δ. This could be either larger or smaller than values suggested in this document. In addition the microarchitecture, by setting VL and TR can determine how much to load from memory for the vop.avv, vopacc.avv, vfop.avv, and vfopacc.avv instructions, for example, using a longer load for Δ=4 as suggested earlier, or to do multiple outer product accumulations to the same accumulators.
i becomes
row i−1 and the last row is filled with zero).
i becomes
col i−1 and the last column is filled with zero).
i becomes
row i−1 and the last row is filled with zero).
i becomes
row i−1 and the last row is filled with zero). This
instruction is intended for context switch.
The width of accumulators is sufficient to support int32 or FP32 for integer or floating-point accumulation. Any accumulation to int64 or FP64 would use pairs of accumulators, but this is not an expected use case. Accumulators might have a different internal format than int32 or FP32. If not, then accumulators would be exactly accrows × (acccolb / 4). This proposal recommends sizing accumulator array to V×V to match the load bandwidth for the minimum SEW supported (i.e., MLEN/SEWmin), or to 2V×2V to double element reuse and halve the energy associated with DRAM reads, but implementations might choose smaller accumulator arrays to save area, or yet larger ones for even greater energy savings. Such microarchitectural flexibility is an explicit goal of this proposal.
Accumulators are cheap enough when integrated into the multiply/add array that the question should be not be how to eliminate them, but whether it makes sense to quadruple the number. This would allow 𝐶 tiles of and thus twice the element reuse and energy savings that results. To simply obtain energy savings, vectors of elements would be loaded from 𝐴 and 𝐵 and the multiply/add array would be used eight times (instead of twice) to accumulate the outer product. This requires eight accumulators per multiply/add units. The computation is no longer balanced, as the loads take four cycles and computation eight cycles. This further has the advantage of naturally matching the Δ=4 case. Balance can be restored by doubling the number of multiply/add units, to achieve four cycles rather than eight, and Δ=4 is still naturally handled. The disadvantage of taking the outer product of elements rather than 𝑉 elements is simply the 4× storage required for the accumulator array. The advantages of the bigger outer product are enumerated below:
Some implementations may choose to use a smaller multiply/add array than what is required to reach the load bandwidth limit due to area constraints, i.e. choose a multiply/add array smaller than for or for . In this case, the outer product method would typically still load 𝑉 elements from each of 𝐴 and 𝐵. There are two options once the vectors are loaded. The first option maintains a V×V tile size and thus accumulators and iterates the implementation’s multiply/add array multiple times to compute this tile. The second option reduces the tile size to reduce the number of accumulators, and instead uses the extra loaded elements as if they were loaded on subsequent iterations for the smaller tile. For the first option, the outerproduct instruction takes more cycles. For the second option, smaller tiles result in (V/T)2 times as many tile computations.
The first option is appropriate when accumulators are possible, but the multiply/add units are limited. In this case, , and the multiply/add array is used times on all combinations from the two vectors into a tile of 𝐶. This option reduces the number of times source data from 𝐴 and 𝐵 has to be loaded. Each element is used 𝑉 times rather than only the 𝑇 times of the first option.
The LBMA column is the number of multiply/add units required to match the load bandwidth. The MA column is the number provided by a sub-bandwidth implementation, possibly organized as indicated in the array column. The Cycles Ld gives the cycles to load the vectors, and the Cycles MA gives the cycles to use the array to compute the tile. The Rel column gives the cycle multiple of the overall computation relative to the full array case, and is equal to the LBMA/MA ratio and also equal to the CyclesMA/CyclesLd ratio.
| Type | Δ | V | LBMA | MA | C tile | array | Cycles | Rel | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| C | A | B | Ld | MA | |||||||
| int32 | int8 | int8 | 1 | 64 | 2048 | 2048 | 64×64 | 64×32 | 2 | 2 | 1 |
| 1024 | 32×32 | 2 | 4 | 2 | |||||||
| 512 | 32×16 | 2 | 8 | 4 | |||||||
| 256 | 16×16 | 2 | 16 | 8 | |||||||
| 128 | 16×8 | 2 | 32 | 16 | |||||||
| TF32 | BF16 | BF16 | 2 | 32 | 512 | 512 | 32×32 | 32×16 | 2 | 2 | 1 |
| 256 | 32×8 | 2 | 4 | 2 | |||||||
| 128 | 16×8 | 2 | 8 | 4 | |||||||
| FP32 | BF16 | BF16 | 4 | 32 | 512 | 512 | 64×64 | 32×16 | 4 | 16 | 1 |
| 2×32×32 | 4 | 4 | 1 | ||||||||
| 256 | 32×32 | 32×8 | 2 | 4 | 2 | ||||||
| 128 | 16×8 | 2 | 8 | 4 | |||||||
| 64 | 8×8 | 2 | 16 | 8 | |||||||
| FP32 | FP32 | FP32 | 4 | 16 | 128 | 128 | 32×32 | 16×8 | 4 | 16 | 1 |
| 2×16×16 | 4 | 4 | 1 | ||||||||
| 64 | 16×16 | 16×4 | 2 | 4 | 2 | ||||||
The second option is appropriate when both accumulator storage and multiply/add units are limited and so targets accumulators () representing a tile of 𝐶 by iterating times to accumulate the outer product of 𝑇 element portions of the loaded vectors using a multiply/add array of . Consider some example cases in the table below.
The LBMA column is the number of multiply/add units required to match the load bandwidth. The MA column is the number provided by a sub-bandwidth implementation, possibly organized as indicated in the array column. The Tile ratio column gives the multiplier on the number of tiles that must be computed. The V/T column specifies the how many outer products are add to the 𝐶 tile. The Cycles Ld gives the cycles to load the vectors, and the Cycles MA gives the cycles to use the array to compute the tile. The Rel column gives the cycle multiple of the overall computation relative to the full array case, and is equal to the LBMA/MA ratio.
| Type | Δ | V | LBMA | MA | C tile | Tile | Use | array | V/T | Cycles | Rel | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | A | B | ratio | Ld | MA | |||||||||
| int32 | int8 | int8 | 1 | 64 | 2048 | 2048 | 64×64 | 1 | 1 | 64×32 | 1 | 2 | 2 | 1 |
| 1024 | 64×64 | 1 | 1 | 32×32 | 1 | 2 | 4 | 2 | ||||||
| 32×32 | 4 | ½ | 32×32 | 2 | 2 | 2 | 2 | |||||||
| 512 | 32×32 | 4 | ½ | 32×16 | 2 | 2 | 4 | 4 | ||||||
| 256 | 16×16 | 16 | ¼ | 16×16 | 4 | 2 | 4 | 8 | ||||||
| 128 | 16×16 | 16 | ¼ | 16×8 | 4 | 2 | 8 | 16 | ||||||
| TF32 | BF16 | BF16 | 2 | 32 | 512 | 512 | 32×32 | 1 | 1 | 32×16 | 1 | 2 | 2 | 1 |
| 256 | 32×32 | 1 | 1 | 32×8 | 1 | 2 | 4 | 2 | ||||||
| 128 | 16×16 | 4 | ½ | 16×8 | 2 | 2 | 8 | 4 | ||||||
| FP32 | BF16 | BF16 | 4 | 32 | 512 | 512 | 64×64 | ¼ | 2 | 32×16 | ½ | 4 | 4 | 1 |
| 512 | 2×32×32 | 2 | 1 | 32×16 | 1 | 4 | 4 | 1 | ||||||
| 256 | 32×32 | 1 | 1 | 32×8 | 1 | 2 | 4 | 2 | ||||||
| 128 | 16×16 | 4 | ½ | 16×8 | 2 | 2 | 8 | 4 | ||||||
| 64 | 16×16 | 4 | ½ | 16×4 | 2 | 2 | 16 | 8 | ||||||
| FP32 | FP32 | FP32 | 4 | 16 | 128 | 128 | 2×16×16 | 2 | 1 | 16×8 | 1 | 4 | 4 | 1 |
| 64 | 16×16 | 1 | 1 | 16×4 | 1 | 2 | 4 | 2 | ||||||
The accumulation formats for all values of SEW and integer and floating-point need to be nailed down. For example, is TF32 used for some accumulation? How many guard bits are required for integer accumulation, and are there any fixed point shifts?
How should BF16 be accommodated? How should the three IEEE 754 binary8p* formats be accommodated?
Does the acc internal representation need to be specified for migration from one RISC‑V implementation to another?
How does the outer product method compare to other methods for matrix multiply? To that end, we need to explore those methods a bit. The following subsections do that.
Other proposals for RISC‑V matrix extensions propose storing
matrixes in the Vector Register File (VRF). For example,
storing 𝐶,
𝐴,
and 𝐵
in the VRF and adding a matrix multiply instruction
that does vd ← vd + matmul(vs1, vs2).
(This is likely implemented by using local accumulators internally with
transfers to/from vd to the local accumulators.) The
problem is the size of the matrixes that can be accommodated by the VRF
limits the performance of this approach. With LMUL=8, there are only 4
vector
registers (v0, v8, v16, v24) available for use, which might be enough
given 3 matrixes, but which might be limiting for scheduling purposes.
LMUL=4 is a safer assumption, since that provides 8 vector registers
(v0, v4, …, v28).
Working an example again might illustrate the issues. To match the outer
product performance, consider using 32×32 tiles of 16‑bit
elements, making each matrix operand 16384 bits (for LMUL=4 this
requires VLEN≥4096), making the VRF at least 131072 bits, which is
large compared to what is required for the outer product method, and
which also does not include the internal array state that is probably
appropriate. The minimum cycle count for this operation
is ,
for 323 multiply/adds,
or
multiply/adds per cycle. The instruction needs to first fill
internal state from vd (this might take 32 cycles),
perform
cycles of computation, and then transfer the internal state back
to vd (another 32 cycles). The fill and unfill would be
pipelined so another tile multiply could start
every
cycles. In addition, 32768 bits would be loaded from memory every 32L
cycles (1024 bits per Δ cycles) to keep the tile multiply
instructions supplied with data. The problems with this approach
include the long cycle count
(perhaps 128 cycles), the state machines to sequence the operations, the
power wasted transferring to and from vd, and the size of
the VRF coupled with VRF entries requiring a minimum of 4 read ports and
2 write ports (and potentially increased in size for renaming). Some
power might be saved by noting that the current read of vd
would be identical to what was just written from the internal array
state, and then skipping writing the same data back to the internal
state. Loading, storing, and operating on matrixes has not provided any
performance improvement (it remains limited by the load bandwidth), but
it has resulted in greater area, poorer energy efficiency, and greater
complexity.
A better way to avoid accumulators would be to use software to perform T
outer product instructions, targeting accumulation in the Vector
Register File (VRF). Again using 32×32 tiles of 16‑bit
elements, software would load 512 bits
from 𝐴,
512 bits
from 𝐵,
compute an outer product in a single instruction that accumulates this
in the tile stored in vd, repeatable every two cycles.
Perhaps LMUL=8 is reasonable in this case. Only the accumulation tile
is 16384 bits, which for LMUL=8 requires VLEN≥2048, leaving the
VRF a less gargantuan 65536 bits. The computation is similar to the
outer product instruction to local accumulators, except that transfers
into and out of the computation array are necessary, costing
considerable time and energy. To solve this problem, add back the
internal array state, and upon noticing that the current read
of vd would be identical to what was just written from the
internal array state, skipping writing the same data back to the
internal state. Once again, this option has not provided any
performance improvement (it remains limited by the load bandwidth), but
it has resulted in greater area, poorer energy efficiency, and greater
complexity. The only savings is to avoid extra state to be context
switched by the supervisor.
Other proposals for RISC‑V matrix extensions propose storing tiles in a Matrix Register File (MRF), either by adding a separate MRF, or mapping the MRF to the existing Vector Register File (VRF).
To keep the math simpler, we analyze only the fully square case and the rectangular case . The computational intensity of the square case is multiply/adds for elements loaded, for a computational intensity of . This is identical to the computational intensity of the outer product method. The computational intensity of the rectangular tile is multiply/adds for elements loaded, for a computational intensity of .
Similarly, for the fully square case is multiply/adds for elements stored in registers which is considerably larger than the vector and outer product accumulator methods.
When the Vector Register File (VRF) is used to store matrixes rather than vectors, the first case is when the VRF size remains the same. Microarchitectures have significant flexibility in choosing the VRF parameters such as VLEN (the VRF size is VLEN×32 bits), so to analyze this case, it is necessary to look at the considerations that typically influence VRF size. Some of these are enumerated below.
Given the above, it is expected that many high-IPC microarchitectures will choose VLEN = MLEN and the analysis will be based on VRFbits=MLEN×32. Conversely, many low-IPC microarchitectures will have VLEN = MLEN×2 for targeting LMUL=2 algorithms or VLEN = MLEN×4 targeting LMUL=1 algorithms, since in both cases there are four cycles to setup the next vector operation to a unit (e.g., multiply/add, load/store), which allows modest instruction level parallelism to accomplish in 6-8 instructions (including loop iteration). Some low-IPC microarchitectures might choose another factor of two, but the analysis here will use VRFbits=MLEN×64 when LMUL=2 algorithms are the primary target, and VRFbits=MLEN×128 when LMUL=1 algorithms are significant. Since this analysis is often based on the VRF size, denoted W, and load bandwidth V, both expressed in elements of EEW bits, then or . For the high-IPC case, may be appropriate.
For a processor with , the VRF can hold three (one wide) square matrixes with . For even powers of two, this is exact (i.e., suggests ), and for odd powers of two, either square tiles with or rectangular tiles, may be used (i.e., for , the tile is ). The following analysis will first consider 𝐶, 𝐴, and 𝐵 all being . A second analysis for 𝐶 being , 𝐴 being , and 𝐵 being is considered. The reader is invited to generalize the dimensions of 𝐴 to , and therefore the dimensions of 𝐵 to or for the two cases.
The product of two matrixes can be done in cycles using pipelined multiply/add units, and the loads of the two source matrixes require cycles. Loads and computation are balanced when . The computation rate is when , and when . For the suggested . the computation is load limited when .
When 𝐶 is 𝐴 will be and 𝐵 will be , where generally , in which case the product can also be done in cycles but in this case using multipliers. The loads of the two source matrixes require cycles. Loads and computation are balanced when . The computation rate is when , and when . The rectangular case doubles the computation rate unless load bandwidth limited, in which case the computation rate increases by only 50%.
The reader is invited to repeat the above analysis for (the case when LMUL=1 algorithms are the primary target on low-IPC processors) and for for high-IPC processors.
For example, given VLEN=1024, MLEN=512, SEW=16, then V=32, W=2048, and T=22. Rounding down to a power of two, matrixes of 16×16 or 16×32 would be stored, with four rows stored in four 1024-bit vector registers. The loading of two 16×16 matrixes takes 16 cycles and the computation takes 16×Δ cycles, and so this implementation is leaving the load bandwidth highly underutilized unless Δ=1. The computation rate is 163/(16×Δ) = 256/Δ multiply/adds per cycle. For comparison, given the same parameters, 32 iterations of the outer product with tile accumulation would use two registers for loads of 32 elements, taking 64 cycles and then an outer product into a 322 = 1024 element accumulator array, taking 32×Δ cycles. This is balanced for Δ=2. The computation rate is 323/(32×Δ) = 1024/Δ multiply/adds per cycle, or four times the rate of doing matrix-matrix products. Note however, that 1024 element accumulation matrix with widening requires the entire VRF in this case, leaving no space for loading the vectors for the outer product. This suggests that the accumulator array should be separate from the VRF for both size and energy efficiency reasons.
An enumeration of choices of VRF parameters and the resulting matrixes that can be stored for various SEW and EEW is given in a separate page Table Comparison of Matrixes in Vector Register File with Outer Product Accumulators, which is meant to be viewed/printed in landscape mode. This table also includes the Outer Product Array (OPA) performance for comparison. As can be seen in the table, the advantage of outer product over matrixes in the VRF increases with DLEN/MLEN/VLEN.
SiFive’s Inner-Product Matrix Extensions proposal to the RISC‑V IME TG is another method based on specialized parallel inner product hardware for two extensions. Xsfvmm32a8i adds sf.vqmmacc*.vv for int32 ← int32 + int8 × int8. Xsfvmm32a16f adds sf.vfwmmacc.vv for fp32 ← fp32 + fp16 × fp16. and sf.vfwmmacc.bf.vv for fp32 ← fp32 + bf16 × bf16. Using LMUL=1 (i.e., VL≤VLEN/SEW), it accumulates to a 23×8 tile of 𝐶, held in 23 vector registers, the product of a 23×VL tile of 𝐴 and a VL×8 tile of 𝐵, held in 8 vector registers. The core multiply/add instructions compute the matrix-vector product where is 1×8, is 1×VL, and 𝐵 is VL×8. These instructions are used 23 times to compute the product of the 𝐴 and 𝐵 tiles. As a refresher, for the general matrix/tile multiply where 𝐶 is m×n, 𝐴 is m×k, and 𝐵 is k×n, the number of multiply/adds is and the latency for a maximally parallel implementation usually has latency using multiply/adds. (As a reminder Δ is the number of cycles between dependent adds.) What is typically done to maximize parallelism is to maximize the tile 𝑚 and 𝑛. It is unusual to maximize the tile 𝑘 in matrix multiplication, since that maximizes the latency. For example, the fully-parallel outer product can be thought of minimizing 𝑘 by picking . The latency of inner products increases linearly with VL. This approach is only advantageous when , and especially when , which is possible when carry-save arithmetic is used for the summation, for example, by using a log tree of 3:2 compressors followed by a single carry-propagate add. This works naturally for integer summation; for floating-point block normalization can be used, aligning all the values to be summed to the largest exponent, followed by integer arithmetic to calculate the sum, which is then normalized and rounded.
The choice of 8 and 23 is based on Vector Register File (VRF) considerations. Since some data formats require quad-widening (e.g., int32 ← int32 + int8 × int8) and LMUL=1, the minimum VLEN for this extension, 256, fits eight 32‑bit values. This determines the number of columns of the accumulation and the number of vector registers to hold the 𝐵 tile. One vector register is required to load rows of the 𝐴 tile. This leaves 23 vector registers for the 𝐶 tile accumulation.
The pseudo-code for this proposal is given below:
for ti ← 0 to m-1 step 23
for tj ← 0 to n-1 step 8
// load 23×8 C tile
v8 ← c[ti+ 0,tj..tj+7]
v9 ← c[ti+ 1,tj..tj+7]
⋮
v30 ← c[ti+22,tj..tj+7]
for tl ← 0 to k-1 step VL
// load 8×VL B tile
v0 ← b[tl..tl+VL-1,tj+0]
v1 ← b[tl..tl+VL-1,tj+1]
v2 ← b[tl..tl+VL-1,tj+2]
v3 ← b[tl..tl+VL-1,tj+3]
v4 ← b[tl..tl+VL-1,tj+4]
v5 ← b[tl..tl+VL-1,tj+5]
v6 ← b[tl..tl+VL-1,tj+6]
v7 ← b[tl..tl+VL-1,tj+7]
// unrolled operations on rows of A and C
v31 ← a[ti+0,tl..tl+VL-1] // vle to load row of A
v8 ← sf.vqmmacc.vv(v8, v31, v0..v7, 0) // 10R1W matrix×vector
v31 ← a[ti+1,tl..tl+VL-1] // vle to load row of A
v9 ← sf.vqmmacc.vv(v9, v31, v0..v7, 0) // 10R1W matrix×vector
⋮
v31 ← a[ti+23,tl..tl+VL-1] // vle to load row of A
v30 ← sf.vqmmacc.vv(v30, v31, v0..v7, 0)// 10R1W matrix×vector
// write back 23×8 C tile
c[ti+ 0,tj..tj+7] ← v8
c[ti+ 1,tj..tj+7] ← v9
⋮
c[ti+22,tj..tj+7] ← v30
The inner loop has:
This is a total of 91 instructions. The number of multiply/adds is 23×8×VL=184×VL. The Computational Intensity (CI) is 184×VL / (31×VL) = 5.935.
When VLEN > 256, another tiling is possible, accumulating to a 15×16 tile of 𝐶, held in 15 vector registers, the product of a 15×VL tile of 𝐴 and a VL×16 tile of 𝐵, held in 16 vector registers. The same matrix-vector product accumulation instructions are used twice, with different offsets into the accumulation vector register. is VL×16. These instruction pairs are used 15 times to compute the product of the 𝐴 and 𝐵 tiles. The number of multiply/adds is 15×16×VL=240×VL. The Computational Intensity (CI) is 240×VL / (31×VL) = 7.742.
for ti ← 0 to m-1 step 15
for tj ← 0 to n-1 step 16
// load 15×16 C tile
v16 ← c[ti+ 0,tj..tj+15] // load C tile into
v17 ← c[ti+ 1,tj..tj+15] // 15 vector registers
⋮ // holding 16 elements each
v30 ← c[ti+14,tj..tj+15]
for tl ← 0 to k-1 step VL
// load 16×VL B tile
v0 ← b[tl..tl+VL-1,tj+0]
v1 ← b[tl..tl+VL-1,tj+1]
⋮
v15 ← b[tl..tl+VL-1,tj+15]
// unrolled operations on rows of A and C
v31 ← a[ti+0,tl..tl+VL-1] // vle to load row of A
v16 ← sf.vqmmacc.vv(v16, v31, v0.. v7, 0) // 10R1W matrix×vector
v16 ← sf.vqmmacc.vv(v16, v31, v8..v15, 1) // 10R1W matrix×vector
v31 ← a[ti+1,tl..tl+VL-1] // vle to load row of A
v17 ← sf.vqmmacc.vv(v17, v31, v0.. v7, 0) // 10R1W matrix×vector
v17 ← sf.vqmmacc.vv(v17, v31, v8..v15, 1) // 10R1W matrix×vector
⋮
v31 ← a[ti+14,tl..tl+VL-1] // vle to load row of A
v30 ← sf.vqmmacc.vv(v30, v31, v0.. v7, 0) // 10R1W matrix×vector
v30 ← sf.vqmmacc.vv(v30, v31, v8..v15, 1) // 10R1W matrix×vector
// write back 15×16 C tile
c[ti+ 0,tj..tj+15] ← v16
c[ti+ 1,tj..tj+15] ← v17
⋮
c[ti+14,tj..tj+15] ← v30
The inner loop has:
This is a total of 98 instructions. The number of multiply/adds is 15×16×VL=240×VL. The Computational Intensity (CI) is 240×VL / (31×VL) = 7.742.
This document henceforth uses Matrix Vector Accumulator (MVA) as the name for the class of extensions that includes Xsfvmm32a8i and Xsfvmm32a16f. We first compare MVA to RISC‑V Vector (RVV) and then to Outer Product Accumulator (OPA) below. We begin the analysis by enumerating the MVA configurations that make sense based on the VLEN/DLEN ratio and IPC.
When VLEN = DLEN×4, the vector loads and matrix-vector product instructions take 4 cycles each, making the loop 124 cycles based on the vector loads, with the 55 other instructions instructions executing in the shadow of the vector loads. Such configurations work for processors supporting IPC≥1. The 18 VRF reads can be accomplished using two even/odd pair ports over four cycles for the 𝐵 tile, and two non-pair read ports. The multiply/add rate is then 240×VL/124 = 1.935×VL = 7.7×DLEN/SEW for VLEN = DLEN×4. Since typical RISC‑V Vector achieves a DLEN/SEW rate, this extension is potentially 7.7× more throughput.
When VLEN = DLEN×2, the vector loads and matrix-vector product instructions take 2 cycles each, making the loop 62 cycles based on the vector loads, with the 55 other instructions executing in the shadow of the vector loads. Such configurations work for processors supporting IPC≥2. The 18 VRF reads can be accomplished using four even/odd pair ports over two cycles for the 𝐵 tile, and two non-pair read ports. The multiply/add rate is then 240×VL/62 = 3.871×VL = 7.7×DLEN/SEW for VLEN = DLEN×2. Thus this configuration is also potentially 7.7× more throughput than RISC‑V Vector, but requires more instructions per cycle and VRF read bandwidth.
When VLEN = DLEN, the vector loads and matrix-vector product instructions take 1 cycle each, making the loop 31 cycles based on the vector loads, with the 55 other instructions executing in the shadow of the vector loads. Such configurations work for processors supporting IPC≥3. The 10 VRF reads can be accomplished using four even/odd pair ports for the 𝐵 tile, and two non-pair read ports. The multiply/add rate is then 184×VL/31 = 5.9×VL = 5.9×DLEN/SEW for VLEN = DLEN. Thus this configuration is also potentially 5.9× more throughput than RISC‑V Vector, but requires still more instructions per cycle and VRF read bandwidth.
For energy efficiency loads from the L2 cache are an important component. For VLEN = 256, each element loaded from the 𝐴 tile is used 8 times and each element loaded from the 𝐵 tile is used 23 times. For example, for 16‑bit data, a 256 KiB L2 cache fitting 256×256 𝐴 and 𝐵 tiles, the L2 is referenced 256/8=32 times for 𝐴 and ⌈256/23⌉=12 times for 𝐵 (total 44). Compared to RISC‑V Vector (RVV), MVA is sometimes requires fewer L2 reads (less energy) and sometimes more L2 reads (more energy). Since RVV does not support quad-widening, so a sf.vqmmacc.vv comparison with SEW=8 EEW=32 is not possible, consider comparing sf.vfwmmacc.bf.vv to the RVV configuration DLEN=256, VLEN=512, SEW=16, EEW=32, LMUL=2: the 𝐶 tile would be 8×32, 𝐴 would be scalar loads each used 32 times, and 𝐵 would be a 32‑element vector loads used 8 times, and the L2 referenced 256/32=8 times for 𝐴 and 256/8=32 for 𝐵 (total 40), making MVA 1.1× the L2 references of RVV. There is a savings is VRF reads: this method requires 1.25 register reads per multiply/add, compared to 2-3 per multiply/add for RVV. VRF writes are 0.29 and 1.1 for inner product vs. RVV, respectively. There are also configurations where the inner product method reduces the L2 references; see the table cited below.
For VLEN > 256, each element loaded from the 𝐴 tile is used 16 times and each element loaded from the 𝐵 tile is used 15 times. For example, for 16‑bit data, a 256 KiB L2 cache fitting 256×256 𝐴 and 𝐵 tiles, the L2 is referenced 256/16=16 times for 𝐴 and ⌈256/15⌉=18 times for 𝐵 (total 34).
When compared to Outer Product Accumulators (OPA), sf.vfwmmacc.bf.vv is generally less performance and more energy. Using the same configuration as above, OPA would accumulate the outer product of 16‑element 𝐴 and 𝐵 vectors into a 16×16 array of 32‑bit accumulators in the 16×8 multiply/add array. Each element of 𝐴 and 𝐵 would be used 16 times, so the L2 reads would be 256/16=16 for 𝐴 and 𝐵. The 44 reads for MVA is 1.4× the 32 reads for OPA (i.e., 40% more energy for L2 access). For 16‑bit data MVA performs 95 multiply/adds per cycle, and OPA performs 128 multiply/adds per cycle, or 1.35× the throughput. The disparity widens as DLEN and VLEN increase; for DLEN=512, VLEN=1024, OPA performs 512 multiply/adds per cycle compared to 190 for MVA, a factor of 2.7×, while MVA requires 2.8× as many L2 accesses. Since MVA and OPA both support quad-widening, it is worth comparing sf.vqmmacc.vv to OPA for this second configuration: MVA is 380 multiply/adds per cycle compared to 2048 for OPA, a factor 10.8×. In addition, MVA makes 11.0× the number of L2 access as OPA.
Since the comparative throughput and L2 accesses of RVV, MVA, and OPA depend quite a bit by IPC, DLEN, VLEN, SEW, and EEW, the separate Table Comparison of Matrix Vector Product Accumulation with Outer Product Accumulation may be useful (landscape mode or a wide screen is necessary for viewing). This table is meant to be representative of what would typically be done; not all possible design choices are incorporated in the table. Below are a few of the lines of that table for SEW=8 EEW=32 IPC=2 and IPC=3. The RVV columns from the table cited above are omitted below because RVV does not support quad-widening (required for the EEW/SEW ratio chosen for sampling). This also keeps the table width consistent with this document.
The Computation Intensity (CI) of IME Option F is 5.935 for the 23×8 𝐶 tile, and 7.742 for the 15×16 𝐶 tile. The CI of the Outer Product Array (OPA) is and is included in the table.
| Base | VRF | MVA | OPA | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IPC | DLEN bits |
VLEN bits |
VRF bytes |
pair ports |
m | n | k | loop cyc |
OP /cyc |
CI | acc | acc bytes |
OP /cyc |
CI | MVA ratio |
load ratio |
| 2 | 256 | 256 | 1024 | 1 | 23 | 8 | 32 | 92 | 128 | 5.9 | 32×32 | 4096 | 1024 | 16 | 8.0× | 2.8× |
| 2 | 256 | 256 | 1024 | 2 | 23 | 8 | 32 | 46 | 256 | 5.9 | 32×32 | 4096 | 1024 | 16 | 4.0× | 2.8× |
| 2 | 256 | 256 | 1024 | 4 | 23 | 8 | 32 | 46 | 256 | 5.9 | 32×32 | 4096 | 1024 | 16 | 4.0× | 2.8× |
| 2 | 256 | 512 | 2048 | 1 | 23 | 8 | 64 | 92 | 256 | 5.9 | 32×32 | 4096 | 1024 | 16 | 4.0× | 2.8× |
| 2 | 256 | 512 | 2048 | 1 | 15 | 16 | 64 | 120 | 256 | 7.7 | 32×32 | 4096 | 1024 | 16 | 4.0× | 2.1× |
| 2 | 256 | 512 | 2048 | 2 | 23 | 8 | 64 | 62 | 380 | 5.9 | 32×32 | 4096 | 1024 | 16 | 2.7× | 2.8× |
| 2 | 256 | 512 | 2048 | 2 | 15 | 16 | 64 | 62 | 495 | 7.7 | 32×32 | 4096 | 1024 | 16 | 2.1× | 2.1× |
| 2 | 256 | 512 | 2048 | 4 | 23 | 8 | 64 | 62 | 380 | 5.9 | 32×32 | 4096 | 1024 | 16 | 2.7× | 2.8× |
| 2 | 256 | 512 | 2048 | 4 | 15 | 16 | 64 | 62 | 495 | 7.7 | 32×32 | 4096 | 1024 | 16 | 2.1× | 2.1× |
| 2 | 512 | 512 | 2048 | 1 | 23 | 8 | 64 | 92 | 256 | 5.9 | 64×64 | 16384 | 4096 | 32 | 16.0× | 5.5× |
| 2 | 512 | 512 | 2048 | 1 | 15 | 16 | 64 | 120 | 256 | 7.7 | 64×64 | 16384 | 4096 | 32 | 16.0× | 4.2× |
| 2 | 512 | 512 | 2048 | 2 | 23 | 8 | 64 | 46 | 512 | 5.9 | 64×64 | 16384 | 4096 | 32 | 8.0× | 5.5× |
| 2 | 512 | 512 | 2048 | 2 | 15 | 16 | 64 | 60 | 512 | 7.7 | 64×64 | 16384 | 4096 | 32 | 8.0× | 4.2× |
| 2 | 512 | 512 | 2048 | 4 | 23 | 8 | 64 | 46 | 512 | 5.9 | 64×64 | 16384 | 4096 | 32 | 8.0× | 5.5× |
| 2 | 512 | 512 | 2048 | 4 | 15 | 16 | 64 | 49 | 627 | 7.7 | 64×64 | 16384 | 4096 | 32 | 6.5× | 4.2× |
| 2 | 512 | 1024 | 4096 | 1 | 23 | 8 | 128 | 92 | 512 | 5.9 | 64×64 | 16384 | 4096 | 32 | 8.0× | 5.5× |
| 2 | 512 | 1024 | 4096 | 1 | 15 | 16 | 128 | 120 | 512 | 7.7 | 64×64 | 16384 | 4096 | 32 | 8.0× | 4.2× |
| 2 | 512 | 1024 | 4096 | 2 | 23 | 8 | 128 | 62 | 760 | 5.9 | 64×64 | 16384 | 4096 | 32 | 5.4× | 5.5× |
| 2 | 512 | 1024 | 4096 | 2 | 15 | 16 | 128 | 62 | 991 | 7.7 | 64×64 | 16384 | 4096 | 32 | 4.1× | 4.2× |
| 2 | 512 | 1024 | 4096 | 4 | 23 | 8 | 128 | 62 | 760 | 5.9 | 64×64 | 16384 | 4096 | 32 | 5.4× | 5.5× |
| 2 | 512 | 1024 | 4096 | 4 | 15 | 16 | 128 | 62 | 991 | 7.7 | 64×64 | 16384 | 4096 | 32 | 4.1× | 4.2× |
| Base | VRF | MVA | OPA | |||||||||||||
| IPC | DLEN bits |
VLEN bits |
VRF bytes |
pair ports |
m | n | k | loop cyc |
OP /cyc |
CI | acc | acc bytes |
OP /cyc |
CI | MVA ratio |
load ratio |
| 3 | 256 | 256 | 1024 | 1 | 23 | 8 | 32 | 92 | 128 | 5.9 | 32×32 | 4096 | 1024 | 16 | 8.0× | 2.8× |
| 3 | 256 | 256 | 1024 | 2 | 23 | 8 | 32 | 46 | 256 | 5.9 | 32×32 | 4096 | 1024 | 16 | 4.0× | 2.8× |
| 3 | 256 | 256 | 1024 | 4 | 23 | 8 | 32 | 31 | 380 | 5.9 | 32×32 | 4096 | 1024 | 16 | 2.7× | 2.8× |
| 3 | 256 | 512 | 2048 | 1 | 23 | 8 | 64 | 92 | 256 | 5.9 | 32×32 | 4096 | 1024 | 16 | 4.0× | 2.8× |
| 3 | 256 | 512 | 2048 | 1 | 15 | 16 | 64 | 120 | 256 | 7.7 | 32×32 | 4096 | 1024 | 16 | 4.0× | 2.1× |
| 3 | 256 | 512 | 2048 | 2 | 23 | 8 | 64 | 62 | 380 | 5.9 | 32×32 | 4096 | 1024 | 16 | 2.7× | 2.8× |
| 3 | 256 | 512 | 2048 | 2 | 15 | 16 | 64 | 62 | 495 | 7.7 | 32×32 | 4096 | 1024 | 16 | 2.1× | 2.1× |
| 3 | 256 | 512 | 2048 | 4 | 23 | 8 | 64 | 62 | 380 | 5.9 | 32×32 | 4096 | 1024 | 16 | 2.7× | 2.8× |
| 3 | 256 | 512 | 2048 | 4 | 15 | 16 | 64 | 62 | 495 | 7.7 | 32×32 | 4096 | 1024 | 16 | 2.1× | 2.1× |
| 3 | 512 | 512 | 2048 | 1 | 23 | 8 | 64 | 92 | 256 | 5.9 | 64×64 | 16384 | 4096 | 32 | 16.0× | 5.5× |
| 3 | 512 | 512 | 2048 | 1 | 15 | 16 | 64 | 120 | 256 | 7.7 | 64×64 | 16384 | 4096 | 32 | 16.0× | 4.2× |
| 3 | 512 | 512 | 2048 | 2 | 23 | 8 | 64 | 46 | 512 | 5.9 | 64×64 | 16384 | 4096 | 32 | 8.0× | 5.5× |
| 3 | 512 | 512 | 2048 | 2 | 15 | 16 | 64 | 60 | 512 | 7.7 | 64×64 | 16384 | 4096 | 32 | 8.0× | 4.2× |
| 3 | 512 | 512 | 2048 | 4 | 23 | 8 | 64 | 31 | 760 | 5.9 | 64×64 | 16384 | 4096 | 32 | 5.4× | 5.5× |
| 3 | 512 | 512 | 2048 | 4 | 15 | 16 | 64 | 33 | 931 | 7.7 | 64×64 | 16384 | 4096 | 32 | 4.4× | 4.2× |
| 3 | 512 | 1024 | 4096 | 1 | 23 | 8 | 128 | 92 | 512 | 5.9 | 64×64 | 16384 | 4096 | 32 | 8.0× | 5.5× |
| 3 | 512 | 1024 | 4096 | 1 | 15 | 16 | 128 | 120 | 512 | 7.7 | 64×64 | 16384 | 4096 | 32 | 8.0× | 4.2× |
| 3 | 512 | 1024 | 4096 | 2 | 23 | 8 | 128 | 62 | 760 | 5.9 | 64×64 | 16384 | 4096 | 32 | 5.4× | 5.5× |
| 3 | 512 | 1024 | 4096 | 2 | 15 | 16 | 128 | 62 | 991 | 7.7 | 64×64 | 16384 | 4096 | 32 | 4.1× | 4.2× |
| 3 | 512 | 1024 | 4096 | 4 | 23 | 8 | 128 | 62 | 760 | 5.9 | 64×64 | 16384 | 4096 | 32 | 5.4× | 5.5× |
| 3 | 512 | 1024 | 4096 | 4 | 15 | 16 | 128 | 62 | 991 | 7.7 | 64×64 | 16384 | 4096 | 32 | 4.1× | 4.2× |
There are a number of pros and cons to this approach:
| Pros | Cons | |
|---|---|---|
| RVV |
|
|
| MVA |
|
|
| OPA |
|
|
Square tiles are generally the best choice, except perhaps for vector where the number of vector registers limits tiles to 16×16 for EMUL≤1 and to 8×8 for EMUL=2. Thus the table below uses square tiles for the Outer Product Array (OPA) and Matrix Register File (MRF) methods below. OPA and MRF are split into Δ≤2 and Δ=4 cases as described in the Matrix Multiply Using An Outer Product Array section above. Δ=3 and Δ≥5 are not considered.
The Acc column gives where tiles are accumulated. The LBM column gives
whether Load Bandwidth Matching is feasible (generally not for Vector
unless the load elements per cycle is small). The C column gives the
number of multiply/add computations per inner loop. The Load column
gives the number of elements loaded per inner loop. The CI column gives
the Computation Intensity (CI), or C/Load. Loading of accumulation tile
is not included in Computational Intensity (CI) because that is
negligible for large matrixes, being outside of the l loop.
The Register Requirement in elements for matching the load bandwidth
limit is given in column RR, except for the vector methods where
matching is generally not feasible. The number of multiply/add units
required to match the load
bandwidth 𝑉
is given in column MAR.
| Method | Acc | LBM | C | Load | CI | RR | MAR | Notes |
|---|---|---|---|---|---|---|---|---|
|
Vector T×T |
VRF | only |
Number of vector registers limits
. Expect for EMUL≤1. Expect for EMUL=2. Usually not feasible to reach load bandwidth limit. RISC‑V requires a scalar register for vector × scalar, hence the rather than etc. for RR. |
|||||
|
Vector T×2T |
only | |||||||
|
Vector T×4T |
only | |||||||
|
OPA T×T Δ≤2 |
ACC | ACC storage cheaper than VRF, and lower power. Matching load bandwidth requires . | ||||||
|
OPA T×T ×2 Δ=4 |
two tiles |
ACC storage cheaper than VRF, and lower power. Matching load bandwidth requires two parallel computations with . |
||||||
|
MRF T×T Δ≤2 |
MRF |
Matching load bandwidth requires large MRF with . |
||||||
|
MRF T×T ×2 Δ=4 |
two tiles |
Matching load bandwidth requires very large MRF. | ||||||
|
MVA 23×8 Δ≪1 |
VRF | — | — | Generally requires block summation |
The comparison finds that vector is limited in its ability to match the load bandwidth. OPA is capable of matching the load bandwidth with minimal VRF usage and a low-power accumulator array, making it superior in all respects to vector. MRF is capable of matching the load bandwidth, but it requires O(V) more register storage in the MRF compared to the OPA VRF requirement, as it requires loading whole matrix tiles before starting an operation, as compared to loading vectors in OPA. The MRF requires up to 3× the bits compared to OPA accumulators because it stores whole 𝐴 and 𝐵 tiles, not just the 𝐶 tile (sometimes less than 3× when the accumulation is in a wider type than the multiplier and multiplicand types). MRF is more complex than OPA (sequencing in hardware rather than software), and likely higher power. OPA is equal or better to MRF in every aspect.
| C type | A type | B type | V | Δ | Method | ACC bits | VRF/MRF bits |
|---|---|---|---|---|---|---|---|
| FP32 | FP32 | FP32 | 16 | 4 | OPA | 8192 | 1024 |
| MRF | 24576 | ||||||
| FP32 | BF16 | BF16 | 32 | 2 | OPA | 32768 | 1024 |
| MRF | 65536 | ||||||
| TF32 | FP8 | FP8 | 64 | 2 | OPA | 77824 | 1024 |
| MRF | 143360 | ||||||
| int32 | int8 | int8 | 64 | 1 | OPA | 131072 | 1024 |
| MRF | 196608 |
This investigation has been primarily about matrix multiplication because O(N3) operations on O(N2) data presents a unique opportunity for performance improvement. Other operations do not present similar O(N) gains. Nonetheless, it is appropriate to at least look at some other operations to see what a matrix extension might include to boost performance less dramatically.
In addition to matrix multiplication, matrix × vector () (where vectors are just matrixes) can be important as well. Unfortunately, the existing RISC‑V Vector ISA already captures most of what can be done. If 𝐴 is an matrix and is a column vector (i.e. a matrix),
then the product is a matrix (i.e., a 𝑚‑element column vector), such that
which is 𝑚 dot products of rows of the matrix with the vector () in parallel. Unfortunately using special-purpose dot product hardware does not speed this computation, as this is load bandwidth limited.
Here the amount of source data is , the number of multiply/adds is . The maximum parallelism is 𝑚, and the minimum latency is . The elements of the matrix are each used exactly once; the only load reuse is on vector elements, which are used 𝑚 times. The parallel computation is the vector scalar products (columns of 𝐴 with vector elements) and the sequential computation is the sum, which is seen in the following reformulation:
where is column 𝑗 of 𝐴, i.e., .
For a load bandwidth of 𝑉 elements per cycle and an add latency of Δ the computation may be pipelined by using multiply/add units over cycles.
Matrix vector products are limited by the matrix load bandwidth, as each element is used exactly once. Improving the performance of this operation requires improving the bandwidth of the matrix storage. If the load bandwidth is 𝑉 elements per cycle, then the RISC‑V vector ISA is sufficient when >2× widening is not required and whenever the vector unit can perform 𝑉 multiply/adds per cycle and a vector register can hold elements, which is true of most vector implementations (e.g., by using LMUL≥Δ). The pseudo-code below for matrix × vector calculation without vector reuse is vectorized in the following transformations. The scalar code
for i ← 0 to m-1
for j ← 0 to n-1
c[i] ← c[i] + a[i,j] * x[j]
is converted to use an accumulator:
for i ← 0 to m-1
acc ← c[i]
for j ← 0 to n-1
acc ← acc + a[i,j] * x[j]
c[i] ← acc
and then vectorized:
for i ← 0 to m-1 step VLA
acc ← c[i..i+VLA-1] // vector load
for j ← 0 to n-1
xj ← x[j] // scalar load
if xj ≠ 0
va ← a[i..i+VLA-1,j] // vector load
acc ← acc + va * xj // vector × scalar accumulate
c[i..i+VLA+1] ← acc // vector store
The above requires only two vector registers for acc and
loading from a. Without widening, RISC‑V allows
LMUL=EMUL=8, providing four
registers (v0, v8, v16,
and v24). This allows VLA to
be VLEN*8/SEW. In most vector configurations, it would
take at least 8 cycles for loading from a, and one cycle for
loading the scalar x[j]. Thus without widening there is
sufficient time to satisfy the add recurrence of Δ cycles from one
loop iteration to the next for most floating-point implementations
(typically Δ≤4). When widening is required, LMUL=4, EMUL=8
would be used, and typically VLA and x[j]
would require at least 5 cycles
so
is still non-blocking.
The above exposition did not attempt to achieve any energy savings from vector element reuse. Code to achieve that is shown next. Start from the accumulator version below:
for i ← 0 to m-1
acc ← c[i]
for j ← 0 to n-1
acc ← acc + a[i,j] * x[j]
c[i] ← acc
Transform to use reuse x vector loads m times
by using a vector register to hold slices of x:
for tj ← 0 to n-1 step VLX
vx ← x[tj..tj+VLX-1]
for i ← 0 to m-1
acc ← c[i]
for j ← 0 to VLX-1
acc ← acc + a[i,tj+j] * vx[j]
c[i] ← acc
Note that this
introduces
extra loads and stores of c. Note also that this depends
on using an indexed element of a vector register as a scalar operand,
which is not part of RISC‑V Vector ISA (but perhaps could be
added). This is then vectorized:
for tj ← 0 to n-1 step VLX
vx ← x[tj..tj+VLX-1]
for i ← 0 to m-1 step VLA
acc ← c[i..i+VLA-1]
for j ← 0 to n-1
acc ← acc + a[i..i+VLA-1,tj+j] * vx[j]
c[i..i+VLA+1] ← acc
The above requires only three vector registers
for vx, acc, and loading from a.
Without widening, this allows both VLX and VLA
to be VLEN*8/SEW, and therefore vx can hold
that number of elements of x for reuse. The matrix loads
take VLEN*8/(V*SEW) cycles, which is in most vector
configurations is ≥8 cycles. This is sufficient time to satisfy
the add recurrence of Δ cycles for most floating-point
implementations (typically Δ≤4). When widening is required,
LMUL=4, EMUL=8 would be used, and VLEN*4/SEW elements
of x are reused and in the typical vector configurations
the loads take at least 4 cycles, and
so
is still non-blocking.
The trouble with the above RISC‑V Vector extension is the number of operands required (vd, vs1, vs2, and an rs3 for j). An immediate could be substituted for rs3, but this would require unrolling the loop:
for tj ← 0 to n-1 step VLX
vx ← x[tj..tj+VLX-1]
for i ← 0 to m-1 step VLA
acc ← c[i..i+VLA-1]
for j ← 0 to n-1
acc ← acc + a[i..i+VLA-1,tj+j] * vx[0]
acc ← acc + a[i..i+VLA-1,tj+j] * vx[1]
⋮
acc ← acc + a[i..i+VLA-1,tj+j] * vx[VLX-1]
c[i..i+VLA+1] ← acc
A second change to RISC‑V Vector would be to allow widening
multiply/add with LMUL=8, so EMUL=16 to double the number of elements of
x that are used. For example, then v0..v15 could
hold acc, v16..v23 could hold x,
and v24..v31 could hold the vector loaded
from a. This assumes that software pipelining is not
required.
Reusing x vector loads only marginally improves the compute
intensity; it is primarily done to improve energy efficiency.
To avoid the need for an addition to the RISC‑V vector ISA, it is possible to use the floating-point scalar registers for VLX=32 (or VLX=32*64/SEW—see below). This requires many scalar floating-point loads, or a vector load and transfers to scalar registers, both of which add overhead similar to performing a single scalar load in the inner loop, but there may be microarchitectures where the following is appropriate.
for tj ← 0 to n-1 step 32
f0 ← x[tj+ 0]
f1 ← x[tj+ 1]
⋮
f31 ← x[tj+31]
for i ← 0 to m-1 step VLA
acc ← c[i..i+VLA-1]
acc ← acc + a[i..i+VLA-1,tj+ 0] * f0
acc ← acc + a[i..i+VLA-1,tj+ 1] * f1
⋮
acc ← acc + a[i..i+VLA-1,tj+31] * f31
c[i..i+VLA+1] ← acc
For SEW < 64 it would be possible to add a RISC‑V vector extension to pack 64/SEW (2, 4, or 8) values into the f registers by loading with FLD, and then the extension would allow .vf to specify a 3-bit immediate specifying which portion of the f register to use as the scalar operand (and disabling the RISC‑V NaN-boxing check for this packed SIMD reference). This might require a wider vector instruction word. However, if RISC‑V Vector were to be extended, supporting elements from a vector register as scalars would be preferable.
There was one qualification in the previous section, which was that accumulation was non-widening or only used the 2× widening supported by RISC‑V Vector. When >2× widening is required, RISC‑V Vector is no longer sufficient. For this case, we turn to the matrix accumulators, which support much wider accumulation than the Vector Register File. We treat the TR×TC accumulators as a vector, rather than as a matrix. This use case is most appropriate when there are Δ times more accumulators than multiply/add units, as occurs naturally for integer (Δ=1), but may be the case for some floating-point configurations. For example, a V×V multiply/add array with four accumulators per multiply/add to implement a 2V×2V accumulation tile for the outer product instructions can support Δ=4 for the matrix vector product. This is illustrated below in pseudo-code (however, the matrix would typically be transposed for unstrided access):
VL ← min(TR*TC, VLEN/SEW*8) // limit to LMUL=8 for vector load
for j ← 0 to m step VL
acc[0..VL−1] ← y[j..j+VL−1] // vector load
for i ← 0 to n
xi ← x[i] // scalar load
if xi ≠ 0
v0 ← a[j..j+VL−1,i] // vector load
acc ← acc + v0 * xi // vector × scalar accumulate in array
y[j..j+VL−1] ← acc // vector store
The additional instructions for the vector scalar product in the array are vmacc.avx vs1, rs2 and vfmacc.avf vs1, fs2.
It might be useful to be able to use more of the accumulator array than
VLEN*LMUL/SEW to increase x[i] reuse. In this case
the vmacc.avx vs1, rs2
and vfmacc.avf vs1, fs2
instructions would be augmented with an offset:
VL ← VLEN/SEW*8 // limit to LMUL=8 for vector load
for j ← 0 to m step VL*4
acc[ 0.. VL−1] ← y[ j..j+ VL−1] // vector load / acc write
acc[ VL..2*VL−1] ← y[ VL+j..j+2*VL−1] // vector load / acc write
acc[2*VL..2*VL−1] ← y[2*VL+j..j+3*VL−1] // vector load / acc write
acc[3*VL..4*VL−1] ← y[3*VL+j..j+4*VL−1] // vector load / acc write
for i ← 0 to n
xi ← x[i]
if xi ≠ 0
v0 ← a[j ..j+ VL−1,i] // vector load
v8 ← a[j+ VL..j+2*VL−1,i] // vector load
v16 ← a[j+2*VL..j+3*VL−1,i] // vector load
v24 ← a[j+3*VL..j+4*VL−1,i] // vector load
acc[0] ← acc[0] + v0 * x[i] // vector scalar product in array
acc[1] ← acc[1] + v8 * x[i] // vector scalar product in array
acc[2] ← acc[2] + v16 * x[i] // vector scalar product in array
acc[3] ← acc[3] + v24 * x[i] // vector scalar product in array
y[ j..j+ VL−1] ← acc[ 0.. VL−1] // acc read / vector store
y[ VL+j..j+2*VL−1] ← acc[ VL..2*VL−1] // acc read / vector store
y[2*VL+j..j+3*VL−1] ← acc[2*VL..2*VL−1] // acc read / vector store
y[3*VL+j..j+4*VL−1] ← acc[3*VL..4*VL−1] // acc read / vector store
For example, when MLEN=512, SEW=8, VLEN=MLEN×2 then V=MLEN/SEW=64,
VLEN=1024, TR=TC=128, so there are 16384 accumulators in a 64×64
MAC array. When this array is used for FP4 matrix data instead of FP8
data (the vector still FP8), then VL=1024*8/4=2048, so the above loop
only uses ⅛ of the accumulators and the Δ=4 constraint is
satisfied. If the number of accumulators is known (e.g., compiled for a
particular target, and not a distro binary), then it probably the case
that the j loop can be completely unrolled, to use a larger
fraction of the accumulator array for the entire vector.
Batched matrix vector product refers to taking the product of multiple
vectors with a given matrix. Batched matrix×vector are just matrix
multiplies, and so an outer product array may be used. However, if the
batch size is small, it may be that other methods are appropriate. For
a batch size p, each matrix element is used p
times.
Consideration of batched matrix × vector alternatives to the outer product is TBD. This author thinks such alternatives are unlikely to be helpful, but until further investigation, this is not certain.
Matrix transpose is typically used to rearrange data for efficient stride-1 access and maximize caching and prefetch opportunities. Matrix transpose is typically done by transposing tiles, where the tile size is related to the cache block size. Transpose gets harder as the element size gets smaller. If the cache block size is CB bits and bits per element is SEW, then the best transpose tile size is T×T where T=CB/SEW. This reads T cache blocks from the source and writes the same number of cache blocks transposed at the destination. In between T buffers, each of CB bits, are required, to group the incoming cache blocks into new cache blocks. The total storage requirement is CB2/SEW. As SEW gets small, CB/SEW and CB2/SEW get big, which is the challenge. This storage requirement is related to the storage required for the outer product accumulator array when load and compute are balanced. A typical vector load might load CB bits, i.e., V=CB/SEW. Then a V×V accumulator tile is exactly the right size for transpose. Moreover the wires for writing columns of those accumulators from a row in register file already exist since they are required for the outer product. The basic transpose consists of a loop iterating V times, loading V elements, and writing to one column of accumulators. At the end of the loop the accumulators are filled with the transpose tile, so read them out a row at a time and write as V elements (i.e., a cache block). If the microarchitecture pipelines these operations appropriately, the transpose can operate at the memory limit.
The above is illustrated by the following pseudo-code transformations. First the classic, simple transpose:
for i ← 0 to n-1
for j ← 0 to m-1
c[j,i] = a[i,j]
This is tiled as follows:
for ti ← 0 to n-1 step T // tile i
for tj ← 0 to m-1 step T // tile j
// transpose tile from a to c
for i ← 0 to T-1
for j ← 0 to T-1
c[tj+j,ti+i] = a[ti+i,tj+j]
The outer product accumulator array can then be used to perform loads and stores T elements at a time:
for ti ← 0 to n-1 step T
for tj ← 0 to m-1 step T
for i ← 0 to T-1
va ← a[ti+i,tj..tj+T-1] // T-element vector load
acc[0..T-1,i] ← va // T-element acc write
for i ← 0 to T-1
va ← acc[i,0..T-1] // T-element acc read
c[tj..tj+T-1] ← va // T-element vector store
Widening vector operations are already awkward in RISC‑V Vector, requiring significant complication and cost in the ISA and implementations both, and RISC‑V Vector only supports 2× widening (i.e., EEW=SEW×2). However, there is actually a need for 4× widening, and perhaps even 8×. For example, the product of two 8‑bit integers is 16 bits, and accumulating 4096 of these requires a 28‑bit accumulator. The product of two 4‑bit integers is 8 bits, and accumulating the same number of these products requires 20 bits, which is 5× widening. This is unlikely to be useful when targeting a RISC‑V vector register directly due to the number of cycles it would take.
Once again, an accumulator array can provide a good solution because of the bandwidth and width they provide. If products are accumulated in the matrix accumulators for hundreds or thousands of iterations, and only after exiting the loop are the wide accumulated values written back to a vector register, it is reasonable to provide 4× or 8× widening, and the cycles to write wide results back to vector registers is insignificant. The writing back may also involve a format conversion, reducing the write cycles. For example, accumulation of FP8 (e.g., binary8p5 or binary8p4) data might be done in integer format, and only converted back to a FP8, FP16, or BF16 when read out the accumulators. Accumulation that occurs in FP32 format might similarly be converted to FP16 or BF16 when written to vector registers.
While it unclear that matrix addition is needed for the applications for which this extension is targeted, should it be required for some other applications, then it is possible to implement multiple accumulators in each computational unit of the two-dimensional array, each capable of holding a value. The accumulators are then a local register file for each unit. Matrix addition and subtraction, and multiplication (for the Hadamard product ⊙) are then operations between local register file entries. Scaling might be based on a global value from the Vector Register File.
These operations are not useful for computation on matrixes that must be read and written to memory, since those operations are memory bandwidth limited, and so RISC‑V vector has compute equal to the load bandwidth. The primary value of these operations would be for complex matrix expressions, e.g., , especially ones that include the result of a matrix multiply and thus a favorable multiply/add to load ratio. Even to do , the product tile of would be computed from T outer product operations, and the result transferred back to a vector register one row at a time, and a row of subtracted. Thus matrix operations other than multiply have limited utility, but can be supported when that utility exists.
It is also possible to imagine operations that operate between adjacent rows and columns. For example, one could absolute differences or squared differences between matrixes, then shift a row or a column, for the purposes of doing motion estimation. This would also require some sort of row or column reduction to compute sum of absolute differences.
The addition of such features would take this extension a little bit
towards a more
general SIMT
approach.
TBD
TBD
This proposal has focused on tiling for the datapath execution units, and in particular for an Outer Product Array (OPA). Additional tiling may be appropriate for caches up to and including the Last Level Cache (LLC). For example, a last level tile size of 2048×2048 FP8 values might be used with a LLC of 16 MiB, using about 4 MiB for the 𝐴 matrix and 4 MiB for the 𝐵 matrix. The 𝐶 datapath tiles would also compete for this cache space, but would not particularly benefit from it, since each 𝐶 datapath tile is read once and written once, whereas for 64×64 datapath tiles, the LLC would source these from 𝐴 and 𝐵 32 times (2048/64) before the outermost loop moves on to a new set of 2048×2048 of tiles. The RISC‑V Zihintntl extension (Non-Temporal Locality Hints) might be used before 𝐶 tile vector loads and stores, in particular the NTL.PALL instruction. Tiling 𝐴 and 𝐵 for the cache hierarchy is likely to save considerable energy. With care and sufficient associativity, it may even be possible to have the 𝐴 and 𝐵 tiles occupy the entire LLC, not just half, enabling a 8 MiB LLC to be useful for 2048×2048 last level tiles.
Another tiling consideration is sharing. A LLC cache shared by multiple processors may suggest tiling appropriate to the fraction of the processors sharing the cache if all processors are very active. However, if the processors are working on matrix multiply in parallel, then it may be appropriate to arrange them to be working on different 𝐶 tiles that share 𝐴 or 𝐵 tiles with the other processors.
Still another tiling consideration is prefetching. While processing 𝐴 and 𝐵 tiles, it may be advantageous to prefetch the next 𝐴 and 𝐵 tiles, so that the computation proceeds in a pipelined fashion. In this case it is appropriate to use half the cache for the working tiles and half for the next tiles. This assumes that the L3 cache has sufficient bandwidth to supply the L2 with data and write the data prefetched from main memory.
| L3 | SEW | EEW | C | A | B | A+B | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 MiB | 8 | 32 | 1024×1024 | 4 MiB | 200% | 1024×1024 | 1 MiB | 50% | 1024×1024 | 1 MiB | 50% | 2 MiB | 100% |
| 2 MiB | 16 | 32 | 1024×1024 | 4 MiB | 200% | 1024×512 | 1 MiB | 50% | 512×1024 | 1 MiB | 50% | 2 MiB | 100% |
| 2 MiB | 32 | 32 | 512×512 | 1 MiB | 50% | 512×512 | 1 MiB | 50% | 512×512 | 1 MiB | 50% | 2 MiB | 100% |
| 2 MiB | 32 | 64 | 512×512 | 2 MiB | 100% | 512×512 | 1 MiB | 50% | 512×512 | 1 MiB | 50% | 2 MiB | 100% |
| 2 MiB | 64 | 64 | 512×512 | 2 MiB | 100% | 512×256 | 1 MiB | 50% | 256×512 | 1 MiB | 50% | 2 MiB | 100% |
| 4 MiB | 8 | 32 | 2048×2048 | 16 MiB | 400% | 2048×1024 | 2 MiB | 50% | 1024×2048 | 2 MiB | 50% | 4 MiB | 100% |
| 4 MiB | 16 | 32 | 1024×1024 | 4 MiB | 100% | 1024×1024 | 2 MiB | 50% | 1024×1024 | 2 MiB | 50% | 4 MiB | 100% |
| 4 MiB | 32 | 32 | 1024×1024 | 4 MiB | 100% | 1024×512 | 2 MiB | 50% | 512×1024 | 2 MiB | 50% | 4 MiB | 100% |
| 4 MiB | 32 | 64 | 1024×1024 | 8 MiB | 200% | 1024×512 | 2 MiB | 50% | 512×1024 | 2 MiB | 50% | 4 MiB | 100% |
| 4 MiB | 64 | 64 | 512×512 | 2 MiB | 50% | 512×512 | 2 MiB | 50% | 512×512 | 2 MiB | 50% | 4 MiB | 100% |
| 8 MiB | 8 | 32 | 2048×2048 | 16 MiB | 200% | 2048×2048 | 4 MiB | 50% | 2048×2048 | 4 MiB | 50% | 8 MiB | 100% |
| 8 MiB | 16 | 32 | 2048×2048 | 16 MiB | 200% | 2048×1024 | 4 MiB | 50% | 1024×2048 | 4 MiB | 50% | 8 MiB | 100% |
| 8 MiB | 32 | 32 | 1024×1024 | 4 MiB | 50% | 1024×1024 | 4 MiB | 50% | 1024×1024 | 4 MiB | 50% | 8 MiB | 100% |
| 8 MiB | 32 | 64 | 1024×1024 | 8 MiB | 100% | 1024×1024 | 4 MiB | 50% | 1024×1024 | 4 MiB | 50% | 8 MiB | 100% |
| 8 MiB | 64 | 64 | 1024×1024 | 8 MiB | 100% | 1024×512 | 4 MiB | 50% | 512×1024 | 4 MiB | 50% | 8 MiB | 100% |
| 16 MiB | 8 | 32 | 4096×4096 | 64 MiB | 400% | 4096×2048 | 8 MiB | 50% | 2048×4096 | 8 MiB | 50% | 16 MiB | 100% |
| 16 MiB | 16 | 32 | 2048×2048 | 16 MiB | 100% | 2048×2048 | 8 MiB | 50% | 2048×2048 | 8 MiB | 50% | 16 MiB | 100% |
| 16 MiB | 32 | 32 | 2048×2048 | 16 MiB | 100% | 2048×1024 | 8 MiB | 50% | 1024×2048 | 8 MiB | 50% | 16 MiB | 100% |
| 16 MiB | 32 | 64 | 2048×2048 | 32 MiB | 200% | 2048×1024 | 8 MiB | 50% | 1024×2048 | 8 MiB | 50% | 16 MiB | 100% |
| 16 MiB | 64 | 64 | 1024×1024 | 8 MiB | 50% | 1024×1024 | 8 MiB | 50% | 1024×1024 | 8 MiB | 50% | 16 MiB | 100% |
L2 caches tend to be 256 KiB, 512 KiB, or 1 MiB. For 8-bit data, with sufficient associativity, this will hold 𝐴 and 𝐵 matrixes of 512×256, 512×512, and 1024×512 elements at 100% utilization respectively. For 32×32 outer products, this means 8, 16, or 32 vector loads per L2 cache block fill. For 64×64 outer products, this is 4, 8, or 16 loads, which represents reasonable energy savings for the outer product coupled with L2 tiling. With L3 tiles of 2048×2048, each L3 cache block is filled into the L2 2048/256=8 times or 2048/512=4 times.
The same L3 prefetching consideration applies to L2 tiling. Since the suggested outer product configuration matches compute to load bandwidth, the L2 may be read every cycle. Thus some sort of banking may be required to provide bandwidth for data prefetched from the L3 to be written to the L2 for the next tiles.
| L2 | SEW | EEW | C | A | B | A+B | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 256 KiB | 8 | 32 | 512×512 | 1 MiB | 400% | 512×256 | 128 KiB | 50% | 256×512 | 128 KiB | 50% | 256 KiB | 100% |
| 256 KiB | 16 | 32 | 256×256 | 256 KiB | 100% | 256×256 | 128 KiB | 50% | 256×256 | 128 KiB | 50% | 256 KiB | 100% |
| 256 KiB | 32 | 32 | 256×256 | 256 KiB | 100% | 256×128 | 128 KiB | 50% | 128×256 | 128 KiB | 50% | 256 KiB | 100% |
| 256 KiB | 32 | 64 | 256×256 | 512 KiB | 200% | 256×128 | 128 KiB | 50% | 128×256 | 128 KiB | 50% | 256 KiB | 100% |
| 256 KiB | 64 | 64 | 128×128 | 128 KiB | 50% | 128×128 | 128 KiB | 50% | 128×128 | 128 KiB | 50% | 256 KiB | 100% |
| 512 KiB | 8 | 32 | 512×512 | 1 MiB | 200% | 512×512 | 256 KiB | 50% | 512×512 | 256 KiB | 50% | 512 KiB | 100% |
| 512 KiB | 16 | 32 | 512×512 | 1 MiB | 200% | 512×256 | 256 KiB | 50% | 256×512 | 256 KiB | 50% | 512 KiB | 100% |
| 512 KiB | 32 | 32 | 256×256 | 256 KiB | 50% | 256×256 | 256 KiB | 50% | 256×256 | 256 KiB | 50% | 512 KiB | 100% |
| 512 KiB | 32 | 64 | 256×256 | 512 KiB | 100% | 256×256 | 256 KiB | 50% | 256×256 | 256 KiB | 50% | 512 KiB | 100% |
| 512 KiB | 64 | 64 | 256×256 | 512 KiB | 100% | 256×128 | 256 KiB | 50% | 128×256 | 256 KiB | 50% | 512 KiB | 100% |
| 1 MiB | 8 | 32 | 1024×1024 | 4 MiB | 400% | 1024×512 | 512 KiB | 50% | 512×1024 | 512 KiB | 50% | 1 MiB | 100% |
| 1 MiB | 16 | 32 | 512×512 | 1 MiB | 100% | 512×512 | 512 KiB | 50% | 512×512 | 512 KiB | 50% | 1 MiB | 100% |
| 1 MiB | 32 | 32 | 512×512 | 1 MiB | 100% | 512×256 | 512 KiB | 50% | 256×512 | 512 KiB | 50% | 1 MiB | 100% |
| 1 MiB | 32 | 64 | 512×512 | 2 MiB | 200% | 512×256 | 512 KiB | 50% | 256×512 | 512 KiB | 50% | 1 MiB | 100% |
| 1 MiB | 64 | 64 | 256×256 | 512 KiB | 50% | 256×256 | 512 KiB | 50% | 256×256 | 512 KiB | 50% | 1 MiB | 100% |
Program or compiler directed prefetching may be difficult to interleave with computation. Hardware prefetching based on cache misses occurs too late since the goal is to fetch well ahead of the first miss. Also, simple hardware prefetching may not be able to match the requirements of fetching matrix tiles from main memory, given that the pattern in virtual memory would be ⌈TC/CB⌉ blocks from addresses separated by the number of bytes in a row. A hybrid approach may be able to address the needs of matrix prefetch. Software might program the virtual address of the start, and the number of columns, and the stride between rows, and then a prefetch engine would initiate prefetch based on this specification in parallel with computation, presuming that there is sufficient cache and TLB bandwidth for both. Separate prefetch data structures may be needed for each level of the cache hierarchy used by matrix operations.
Software would program such a prefetch engine with virtual addresses, which would need to be translated. This might present a challenge for a Last Level Cache (LLC) that is shared by multiple processors, as the LLC would not have its own translation. Instead the prefetches for the LLC would have to come from the processors, where translation is available. In this case, some sort of coordination is required to avoid redundant prefetch.
Another possibility is to perform simple transformation when reading from one level of the memory hierarchy and writing a lower level. One transformation might be transposing the matrix data (e.g., of the 𝐵 matrix so that it can be accessed with non-strided loads), or of data expansion (e.g., converting block scaled values to a wider format after scaling). Such transformations would be to a new address, and so would look more like DMA than prefetch. In such cases the target tile would likely be compact, rather than having a large stride between rows, to reduce associativity requirements.
An alternative method in a multiprocessor system would be to use one processor to initiate the prefetches (e.g., with explicit single cache block instructions) on behalf of the other processors. For example, in a 4 processor subsystem, one processor might be responsible for prefetch while three are performing the calculations. The vector and matrix units of the fourth processor would be wasted, however, which may favor the software-directed hardware prefetch described above. In the case of a multi-threaded processor, one thread might be used for prefetch on behalf of the others.
Even with a large outer product array, large matrix multiplications are likely to benefit from using multiple processors in parallel. Very little synchronization is strictly necessary because the data shared is all read-only. (It will help to make sure tiles of 𝐶 are all cache-block aligned to prevent false sharing.) However, when groups of processors share a cache (e.g., the Last Level Cache (LLC)), it is appropriate to share some of the tiles being processed in parallel. For example, 4 processors sharing a L3 cache could all work on 𝐶 tiles in the same row but different columns, which would allow the L3 to have one copy of the 𝐴 tiles of that row while each processor works on different column of 𝐶, and thus column of 𝐵. This may make some synchronization worthwhile, so that one processor is not getting ahead on tiles of 𝐴, and therefore causing other processors to miss. Synchronization with prefetching processors or threads will also be required.
In the case of a prefetch processor/thread, computation processors/threads may move on to the next 𝐶 tile as soon as they finish the current one because the prefetch is already filling reserved cache space for the next tiles, but should not move on to a 𝐶 tile that would displace 𝐴 and 𝐵 tiles that are still being worked on by other processors. Thus processors may get one 𝐶 tile ahead of others, but not two ahead. A simple barrier synchronization method would be for each processor to increment its own 𝐶 tile completion count, then then wait for the counts of the prefetch processor/thread proceeding to reach its level minus one as illustrated by the following C snippet (atomic operations not required):
uint64_t localcount; // stack variable local to thread
uint32_t myid; // my thread index
volatile uint64_t tilecount[NTHREAD*8]; // one tilecount per cache block
⋮
localcount += 1;
tilecount[myid*8] = localcount; // store to show others where we are
for (size_t i = 0; i != NTHREAD; i += 1) {
while (tilecount[i*8] < localcount-1); // wait for others to catch up
} // for i
When a large number of threads are employed, an O(log2N)
barrier might be used instead of an O(N) one, but in most cases N will
be small.
![[Tile Sharing in LLC]](MMparallel.png)
Going from vectors to an outer product multiply/add array with accumulators for tiles allows the implementation to bring significantly more multiply/add units to bear on matrix multiply. We have already seen how to match computation to load bandwidth by providing a large array of multiply/add units (e.g., 32×16 Δ=2 BF16 multiply/add units for a load bandwidth of 512 bits per cycle). To employ 2048 BF16 units instead of 512, it is necessary to double the vector load bandwidth to 1024 bits per cycle, which is possible, but may not be appropriate for the rest of the unit. Moving matrix computation out of the vector unit, with the bandwidth appropriate there is one possibility being explored in the proposed Attached Matrix Extension (AME), but AME only makes sense when the bandwidth to it can be significantly increased relative to the vector unit. AME is still probably best built around outer product arrays sized to the load bandwidth, but for some incremental increase in load bandwidth. For example, it might benefit from a direct connection to HBM3E memory (see below). Even if AME is located outside of a single processor core for such reasons, it still makes sense for it to be built on top of the RISC‑V Vector (RVV) instruction set. If the RVV is too complex for some implementations, a simplified subset (e.g., omitting segmented loads) can be defined as the basis for AME. RVV instructions would be sent to AME for execution, but this would be transparent to software. One avenue for further investigation is whether AME might be able to source from local SRAM storage for one or both matrixes. Local storage of one matrix that will be used multiple times would double the computation rate possible, which may not seem like much, but the energy efficiency might justify it. A unique way to increase bandwidth and save power might be to have SRAM storage located at each node of the outer product array, if an application for such can be found. For example, it might be reasonable to have about 2048 bits of SRAM per tile element (e.g., 256 KiB total for a 32×32 tile array). Whether there is an application for such a configuration is the question; I suspect it is probably too small to be useful. More likely, AME might employ SRAM for tiling as described above, e.g., to hold a 4096×4096 tile of 𝐴 in one SRAM and a 4096×4096 tile of 𝐵 in another. For FP8 data, each SRAM might be 32 MiB to allow the next 4096×4096 tile to be read in parallel with doing outer product operations on the previous read. One challenge in such an approach is keeping the reads from DRAM to this SRAM coherent with the rest of the system, given the data rates involved.
The HBM3E generation of DRAM promises to deliver 1.2 terabytes per second (TB/s). It is interesting to ask what sort of outer product array would be matched to this bandwidth. For a 4 GHz processor, this bandwidth is 300 bytes per cycle. Given the difficulties of hitting peak bandwidth and the appropriateness of powers of two, call this 256 bytes (2048 bits) per cycle. For BF16 data, this calls for a 128×64 Δ=2 outer product array, or for a quad-core with each processor utilizing a 64×32 array. This is feasible in 2024 process nodes using the techniques proposed here. For int8 and fp8 data, 256×128 arrays are required. For 8-bit data, the 256×128 array delivers 65 TOPS/GHz; for example, 262 TOPS at 4 GHz.
|
|
|
<webmaster at securerisc.org> |

|
| 2025-03-25 | |||